OmniHuman-1: AI Video Generation by Bytedance
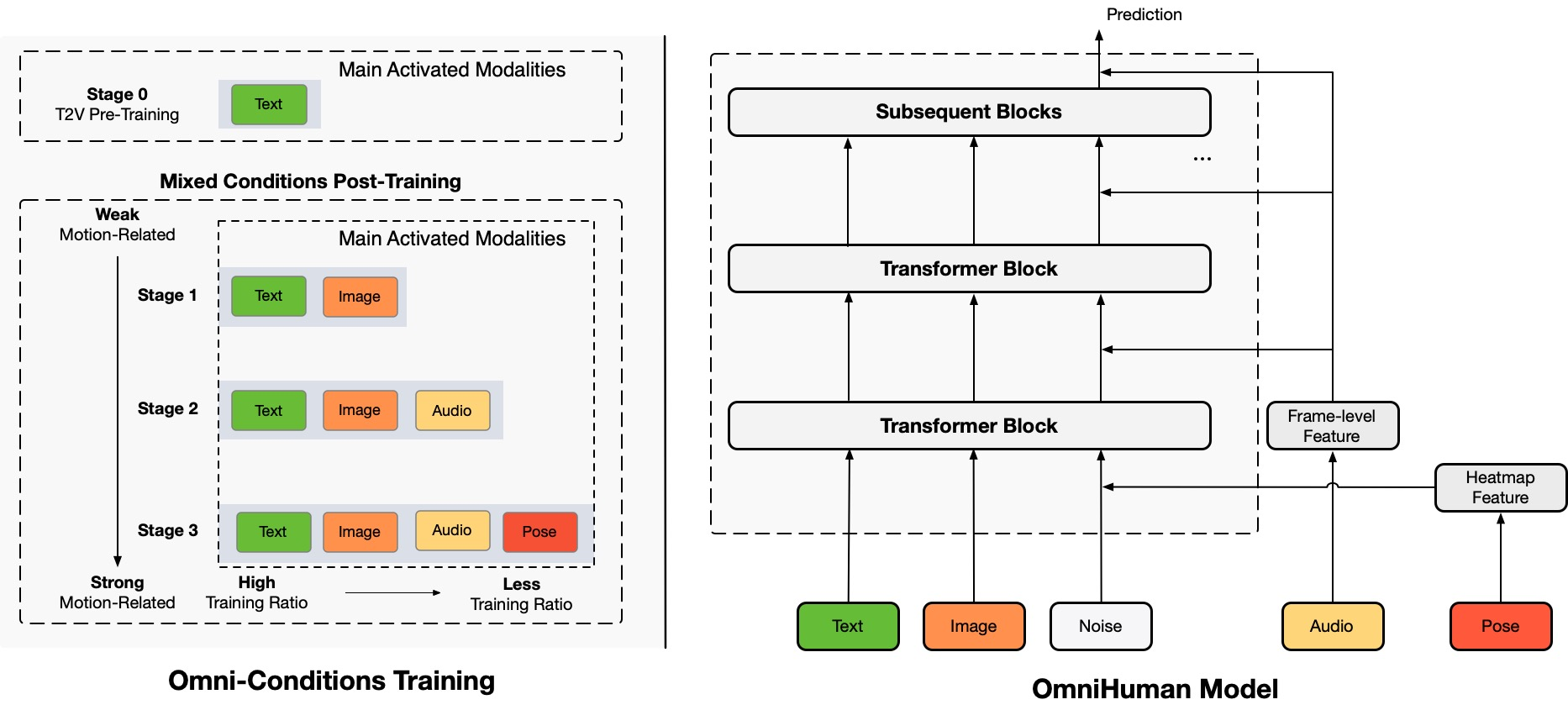
Architecture Overview
TL;DR:Wir schlagen einen End-to-End-Multimodalitäts-bedingten Rahmen für die Erzeugung von Videos von Menschen vor, der OmniHuman genannt wird und Videos von Menschen auf der Grundlage eines einzigen Bildes eines Menschen und von Bewegungssignalen (z. B. nur Audio, nur Video oder eine Kombination aus Audio und Video) erzeugen kann. In OmniHuman führen wir eine gemischte Trainingsstrategie für Multimodalitäts-Bewegungsbedingungen ein, die es dem Modell ermöglicht, von der Datenaufstockung gemischter Bedingungen zu profitieren. Dies überwindet das Problem, dass frühere End-to-End-Ansätze aufgrund der Seltenheit hochwertiger Daten hatten. OmniHuman übertrifft bestehende Methoden erheblich und erzeugt extrem realistische Videos von Menschen auf der Grundlage schwacher Signaleingaben, insbesondere Audio. Es unterstützt Bildeingaben in jedem Seitenverhältnis, ob es sich um Porträts, Halbkörper- oder Ganzkörperbilder handelt, und liefert lebensechtere und qualitativ hochwertigere Ergebnisse in verschiedenen Szenarien.
Erzeugte Videos
OmniHuman unterstützt verschiedene visuelle und auditive Stile. Es kann realistische Videos von Menschen in jedem Seitenverhältnis und jeder Körperproportion (Porträt, Halbkörper, Ganzkörper alles in einem) erzeugen, wobei der Realismus aus umfassenden Aspekten wie Bewegung, Beleuchtung und Texturdetails stammt.
* Bitte beachten Sie, dass zur Erzeugung aller Ergebnisse auf dieser Seite nur ein einzelnes Bild und Audio erforderlich sind, mit Ausnahme der Demo, die Video- und kombinierte Antriebssignale zeigt. Um ein sauberes Layout zu gewährleisten, haben wir die Anzeige der Referenzbilder weggelassen, die in den meisten Fällen das erste Frame des erzeugten Videos sind. Wenn Sie Vergleiche oder weitere Informationen benötigen, zögern Sie bitte nicht, uns zu kontaktieren.
Singen
OmniHuman kann verschiedene Musikstile und mehrere Körperhaltungen und Gesangsformen unterstützen. Es kann hochtönende Lieder bewältigen und verschiedene Bewegungsstile für verschiedene Arten von Musik anzeigen. Denken Sie daran, die höchste Videoqualität auszuwählen. Die Qualität des erzeugten Videos hängt auch stark von der Qualität des Referenzbildes ab.
Sprechen
OmniHuman kann Eingaben in jedem Seitenverhältnis in Bezug auf Sprache unterstützen. Es verbessert die Handhabung von Gesten erheblich, was eine Herausforderung für bestehende Methoden darstellt, und produziert äußerst realistische Ergebnisse. Das Audio und die Bilder für einige der Testfälle stammen aus link1, link2, link3, link4.
Vielfalt
In Bezug auf die Eingabevielfalt unterstützt OmniHuman Zeichentrickfilme, künstliche Objekte, Tiere und herausfordernde Posen und stellt sicher, dass die Bewegungscharakteristiken zu den einzigartigen Merkmalen jedes Stils passen.
Weitere Porträtfälle
Hier haben wir auch einen Abschnitt eingefügt, der sich auf Ergebnisse im Porträt-Seitenverhältnis konzentriert, die aus Testproben in den CelebV-HQ-Datensätzen stammen.
Weitere Halbkörper-Fälle mit Händen
Hier bieten wir auch zusätzliche Beispiele, die speziell Gestenbewegungen zeigen. Einige Eingabebilder und Audios stammen von TED, Pexels und AIGC.
Kompatibilität mit Video-Antrieb
Aufgrund der gemischten Bedingungstrainingsmerkmale von OmniHuman kann es nicht nur Audio-Antrieb, sondern auch Video-Antrieb unterstützen, um spezifische Videoaktionen nachzuahmen, sowie kombinierten Audio- und Video-Antrieb (Fall von link), um spezifische Körperteile wie neuere Methoden zu steuern. Im Folgenden demonstrieren wir diese Fähigkeiten.
Ethische Bedenken
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Wenn Sie dieses Projekt für Ihre Forschung nützlich finden, können Sie uns zitieren und sich unsere anderen verwandten Arbeiten ansehen:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}