OmniHuman-1 : Génération Vidéo AI par ByteDance
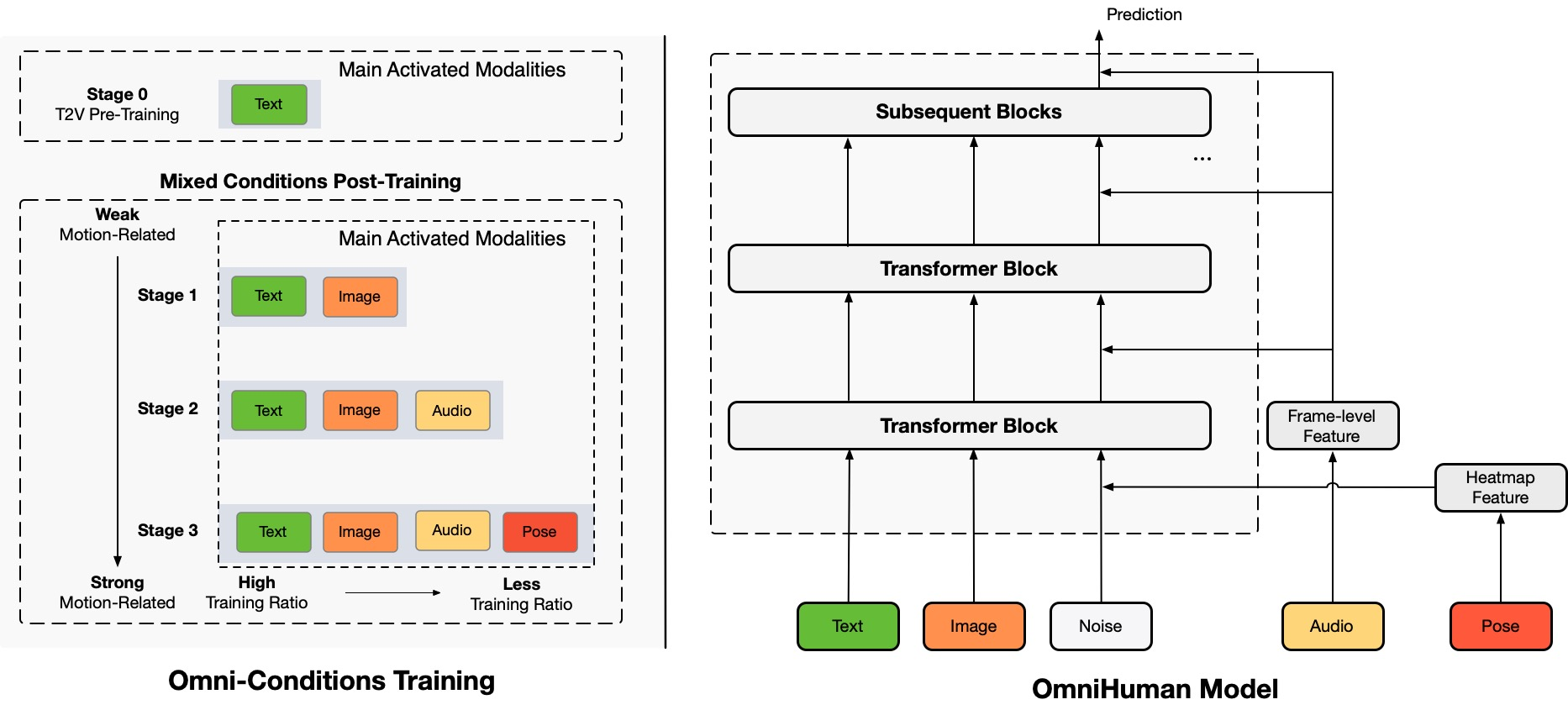
Architecture Overview
TL;DR:Nous proposons un cadre de génération de vidéos humaines conditionné par la multimodalité de bout en bout appelé OmniHuman, qui peut générer des vidéos humaines basées sur une seule image humaine et des signaux de mouvement (par exemple, audio uniquement, vidéo uniquement, ou une combinaison d'audio et de vidéo). Dans OmniHuman, nous introduisons une stratégie d'entraînement mixte de conditionnement de mouvement multimodal, permettant au modèle de bénéficier de la mise à l'échelle des données de conditionnement mixte. Cela surmonte le problème auquel étaient confrontées les approches de bout en bout précédentes en raison de la rareté des données de haute qualité. OmniHuman surpasse considérablement les méthodes existantes, générant des vidéos humaines extrêmement réalistes basées sur des entrées de signaux faibles, en particulier l'audio. Il prend en charge les entrées d'images de toute proportion, qu'il s'agisse de portraits, de demi-corps ou de corps entiers, et offre des résultats plus réalistes et de haute qualité dans divers scénarios.
Vidéos Générées
OmniHuman prend en charge divers styles visuels et audio. Il peut générer des vidéos humaines réalistes dans n'importe quelle proportion et proportion corporelle (portrait, demi-corps, corps entier, tout en un), avec un réalisme provenant d'aspects complets tels que le mouvement, l'éclairage et les détails de texture.
* Note : Pour générer tous les résultats sur cette page, seule une image unique et un audio sont nécessaires, à l'exception de la démo montrant des signaux de conduite vidéo et combinés. Pour une mise en page propre, nous avons omis l'affichage des images de référence, qui sont la première image du vidéo généré dans la plupart des cas. Si vous avez besoin de comparaisons ou d'informations supplémentaires, n'hésitez pas à nous contacter.
Chant
OmniHuman peut prendre en charge divers styles de musique et s'adapter à de multiples poses corporelles et formes de chant. Il peut gérer des chansons à tonalité élevée et afficher différents styles de mouvement pour différents types de musique. N'oubliez pas de sélectionner la meilleure qualité vidéo. La qualité de la vidéo générée dépend également fortement de la qualité de l'image de référence.
Parler
OmniHuman peut prendre en charge les entrées de toute proportion en termes de parole. Il améliore considérablement la gestion des gestes, ce qui est un défi pour les méthodes existantes, et produit des résultats extrêmement réalistes. L'audio et les images pour certains des cas de test proviennent de link1, link2, link3, link4.
Diversité
En termes de diversité des entrées, OmniHuman prend en charge les dessins animés, les objets artificiels, les animaux et les poses difficiles, garantissant que les caractéristiques de mouvement correspondent aux caractéristiques uniques de chaque style.
Plus de Cas de Portraits
Ici, nous incluons également une section dédiée aux résultats de proportion de portrait, qui sont dérivés d'échantillons de test dans les ensembles de données CelebV-HQ.
Plus de Cas de Demi-Corps avec Mains
Ici, nous fournissons également des exemples supplémentaires montrant spécifiquement des mouvements de gestes. Certaines images et audios d'entrée proviennent de TED, Pexels et AIGC.
Compatibilité avec la Conduite Vidéo
Grâce aux caractéristiques d'entraînement de conditionnement mixte d'OmniHuman, il peut prendre en charge non seulement la conduite audio, mais aussi la conduite vidéo pour imiter des actions vidéo spécifiques, ainsi que la conduite combinée audio et vidéo (cas de link) pour contrôler des parties spécifiques du corps comme des méthodes récentes. Ci-dessous, nous démontrons ces capacités.
Préoccupations Éthiques
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Si vous trouvez ce projet utile pour votre recherche, vous pouvez nous citer et consulter nos autres travaux connexes :
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}