
Les Performances Éblouissantes d'OmniHuman-1
</p> Dans les domaines des humains numériques et de la technologie de synchronisation labiale IA, l'équipe AI.TALK, en s'appuyant sur son expertise approfondie dans l'industrie et son expérience pratique étendue, a créé environ 300 humains numériques. Ils ont expérimenté presque toutes les technologies d'humains numériques open source et propriétaires disponibles sur le marché, accumulant une richesse d'expérience pratique. Après avoir participé aux tests bêta d'OmniHuman-1, l'équipe a accordé à ce produit des éloges exceptionnellement élevés,
le considérant comme le meilleur produit d'humain numérique IA disponible aujourd'hui—sans exception.
Est-ce une exagération ? Regardons cet exemple :

La force d'OmniHuman-1 réside dans sa capacité à parfaitement réaliser la synchronisation labiale pour les humains numériques en vue de profil, à reconnaître automatiquement les paroles dans la musique, et à permettre aux humains numériques basés sur des images de se balancer naturellement et d'interagir avec des instruments de musique.
Maintenant, jetons un coup d'œil au segment suivant :
La clarté de sa bouche est exceptionnellement élevée, et même dans des conditions difficiles telles que l'obstruction du microphone ou un éclairage complexe, la synchronisation labiale reste précise. De plus, les personnages peuvent afficher une large gamme d'émotions faciales en synchronisation avec la musique. Ces capacités ont laissé l'équipe en admiration.
Les Percées dans le Surmontement des Défis Techniques
L'équipe a été établie début 2023, et en chemin, ils sont devenus familiers avec et ont testé de nombreux produits bien connus, tels que D-ID et HeyGen. Cependant, ces produits font encore face à plusieurs défis dans les domaines techniques suivants :
- Limitations des Caractéristiques Faciales : Les technologies traditionnelles nécessitent de télécharger des photos frontales claires et non obstruées des individus. Les photos prises de côté ou en angle ascendant entraînent souvent des échecs de reconnaissance. Même si la reconnaissance est à peine réalisée, les résultats générés sont considérablement compromis.
- Limitations Dynamiques : Dans les premières technologies d'humains numériques basées sur des images, les mouvements du corps étaient rigides, avec seulement des mouvements de la tête et de la bouche, manquant de dynamique naturelle des membres.
- Limitations des Pixels : Les méthodes conventionnelles de synchronisation labiale entraînent souvent une dégradation des pixels autour de la bouche, résultant en une sortie floue autour de la bouche, ce qui impacte négativement les résultats créatifs.
- Limitations du Rythme : Lorsque la vitesse de parole audio est trop rapide, la synchronisation labiale de l'humain numérique peut devenir désordonnée, rendant difficile la correspondance avec les mouvements de bouche à haute fréquence.
L'émergence d'OmniHuman-1 a surmonté avec succès ces défis techniques. Il introduit une stratégie de formation hybride conditionnée par le mouvement multimodal, permettant au modèle de bénéficier de l'expansion des données de condition mixte et de résoudre la rareté des données de haute qualité. OmniHuman-1 prend en charge les entrées d'images de tout rapport d'aspect, qu'il s'agisse de portraits, de demi-corps ou d'images en pied, offrant des résultats vivants et de haute qualité dans divers scénarios.
La Valeur Innovante d'OmniHuman-1
Il élimine les restrictions d'angle. Lorsque nous téléchargeons des images pour créer des humains numériques, les plates-formes exigent généralement que les utilisateurs soumettent des photos frontales claires et non obstruées des individus. La raison est simple : le cœur de cette technologie repose sur la reconnaissance précise des caractéristiques faciales. Si elle échoue, des messages comme "Impossible de reconnaître le visage" apparaîtront. Par conséquent, des photos comme celles ci-dessous sont définitivement inacceptables, car les angles de côté ou ascendants entraînent souvent des échecs de reconnaissance. Parfois, avec de la chance, un angle de côté de 45 degrés pourrait être reconnu, mais les résultats générés seront considérablement compromis, avec des problèmes comme des bouches déformées étant courants.


Maintenant, jetons un coup d'œil à la performance d'OmniHuman-1 avec des profils de côté à 90 degrés et des angles ascendants :
La synchronisation labiale dans les deux vidéos est presque parfaite, accompagnée d'une large gamme de mouvements naturels. Notez que ce n'est pas une différence entre une performance forte et faible—c'est une différence entre ce qui est possible et ce qui est impossible.
OmniHuman-1 élimine les restrictions d'angle, permettant aux personnages dans la production de films et de vidéos de "débloquer" une large gamme d'angles de dialogue et de compositions de plans, n'étant plus limités à faire face directement à la caméra. De plus, l'amélioration de la reconnaissance des caractéristiques faciales améliore également la tolérance pour les visages non humains, comme les animaux. Par exemple, un agneau de style 3D peut maintenant réaliser une synchronisation labiale de base et une reconnaissance de dialogue, répondant aux besoins de la création quotidienne.
De plus, l'augmentation de la tolérance pour les caractéristiques faciales se reflète également dans la reconnaissance de différents styles, comme les styles anime 2D et à l'encre mentionnés ci-dessous. Bien que d'autres modèles puissent également générer des mouvements labiaux dans ces styles, en termes de complétude et de dynamique des mouvements du corps, OmniHuman-1 reste le meilleur à l'heure actuelle. Cela mène à la prochaine question concernant les humains numériques basés sur des images.
OmniHuman-1 excelle dans la performance visuelle dynamique au niveau I2V (Image-to-Video). Prenons l'exemple de Sun Wukong (le Roi Singe) : Sa reconnaissance faciale est très précise, et lorsqu'il parle, tout son corps et l'environnement environnant sont en mouvement naturel et à grande amplitude. Le mouvement de haut en bas de sa tête s'intègre parfaitement au rythme de son corps, et même les vagues d'eau se synchronisent avec ses actions, comme si elles conduisaient une génération de vidéo animée à partir d'une seule image.
En termes de musique, OmniHuman-1 a subi une optimisation ciblée. En plus de reconnaître directement les paroles dans la musique, les visages des personnages peuvent également afficher une large gamme d'émotions et prendre en charge le chant et les performances d'instruments à plusieurs personnes.
Sa performance en pixels labiaux est encore plus étonnante. Il conserve non seulement les caractéristiques faciales originales du personnage, mais atteint également un niveau de clarté incroyablement élevé. Par exemple, dans les détails en gros plan de l'animation de Fok et d'une chanteuse, même les dents générées sont reproduites de manière extrêmement naturelle.
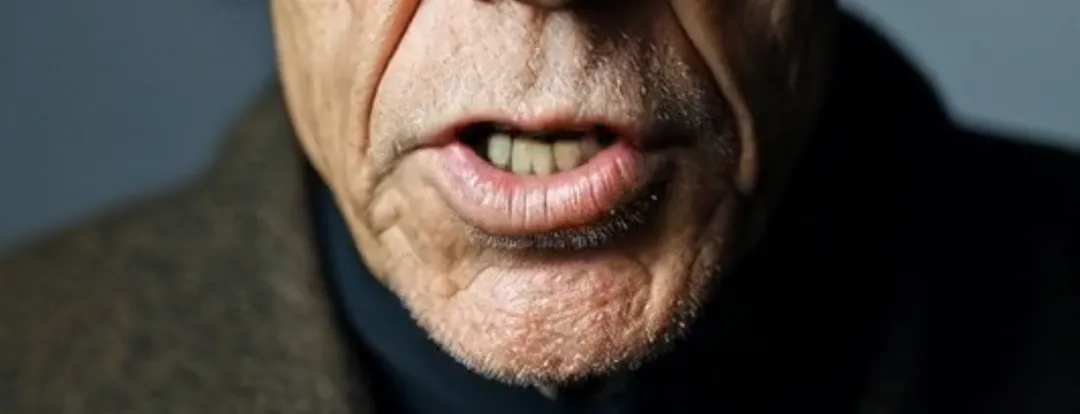
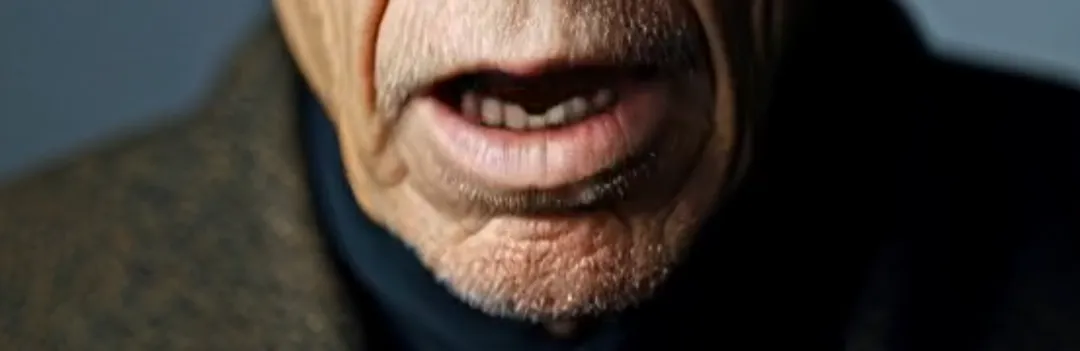



Ensuite, il y a la reconnaissance des pixels, qui implique deux éléments qui interfèrent souvent avec la synchronisation labiale : un éclairage fort et de longues barbes. Le premier peut entraîner l'échec de la génération de vidéos pour les images avec des contrastes intenses de lumière et d'ombre. Dans Runway, cela provoquerait un message "contraste excessif de lumière et d'ombre". Par exemple, dans un échantillon vidéo, une personne âgée assise dans une voiture a des ombres changeantes sur son visage. À part OmniHuman-1, presque aucune autre plate-forme ne peut remplacer avec succès les lèvres. Les longues barbes, d'autre part, provoquent souvent un flou autour de la bouche. Cependant, comme on peut le voir dans les clips échantillons, OmniHuman-1 peut presque parfaitement reproduire les barbes sans aucune perte de détail.
Impressionnant, il n'y a pas d'autres mots pour le décrire.
Le dernier défi est le problème de parler trop rapidement. Toute personne ayant de l'expérience a rencontré cela : lorsque le taux de parole dans l'audio que vous fournissez est trop rapide, la synchronisation labiale de l'humain numérique deviendra définitivement désordonnée. C'est parce que le taux de trame d'animation a du mal à correspondre aux changements à haute fréquence des mouvements labiaux, résultant en une inadéquation. Cependant, OmniHuman-1 a également très bien résolu ce problème. Dans le segment où Steve Jobs parle à un rythme extrêmement rapide, il n'y a presque aucun défaut dans la synchronisation labiale. Même pour la musique rap, cela ne devrait pas poser de problème.
Problèmes Existants et Perspectives Futures
Malgré ses avancées technologiques significatives, OmniHuman-1 a encore des domaines à améliorer. Actuellement, OmniHuman-1 n'offre aucune fonction de réglage fin. Par exemple, lorsque les personnages parlent, l'amplitude de leurs mouvements peut être trop grande. Il est suggéré d'ajouter des options pour régler finement l'amplitude des mouvements du corps et fournir plus de choix pour les actions des membres. De plus, OmniHuman-1 ne prend actuellement en charge que les animations pilotées par des images et ne prend pas encore en charge la synchronisation labiale vidéo. Il est espéré que cette fonctionnalité sera bientôt introduite. La limitation actuelle de 15 secondes pour le contenu généré n'est pas courte, mais il y a encore de la place pour l'amélioration. En termes de vitesse de génération, pendant la phase de test interne, il faut environ 15-20 minutes pour générer un seul clip. Il est espéré que ce processus pourra être optimisé et rendu plus efficace lors du lancement officiel du produit.
Résumé
Avec ses fortes capacités techniques et ses performances exceptionnelles, OmniHuman-1 est sans aucun doute le meilleur produit d'humain numérique IA actuellement disponible. Il a atteint des performances de haut niveau en termes de tolérance des caractéristiques faciales, de précision et d'attrait esthétique, avec des avantages clairs dans les fonctions individuelles. Son lancement devrait considérablement stimuler l'application des humains numériques et des vidéos musicales IA et apporter plus de possibilités à la production cinématographique et télévisuelle. OmniHuman-1 a eu un impact transformateur sur le domaine des humains numériques IA, et nous attendons avec impatience plus de surprises lors de son lancement officiel.
Cet article est adapté du contenu du blogueur Han Qing de AITalk, avec des remerciements spéciaux.