
OmniHuman-1の驚異的なパフォーマンス
</p> デジタルヒューマンとAIリップシンク技術の分野において、AI.TALKチームは、深い業界知識と豊富な実践経験を活かし、約300体のデジタルヒューマンを作成しました。彼らは市場で入手可能なほぼ全てのオープンソースおよびプロプライエタリのデジタルヒューマン技術を試し、豊富な実践経験を積みました。OmniHuman-1のベータテストに参加した後、チームはこの製品に非常に高い評価を与え、
現在利用可能な最高のAIデジタルヒューマン製品であると確信しています。
これは誇張でしょうか?次の例を見てみましょう:

<iframe
style="width: 100%; height: auto; aspect-ratio: 16/9;" src="https://cdn.omnihuman1.org/video/0b2edmabwaaamaapygfymbtvag6ddmnqagya.f10002.mp4"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
</iframe>OmniHuman-1の強みは、デジタルヒューマンの横顔でのリップシンクを完璧に実現し、音楽の歌詞を自動認識し、画像ベースのデジタルヒューマンが自然に揺れ、楽器とインタラクションできる点にあります。
次に、以下のセグメントを見てみましょう:
その口の明瞭度は非常に高く、マイクの遮蔽や複雑な照明条件など、困難な状況下でもリップシンクは正確です。さらに、キャラクターは音楽に合わせて幅広い表情を表示できます。これらの能力はチームを驚かせました。
技術的課題の克服におけるブレークスルー
チームは2023年初頭に設立され、その過程でD-IDやHeyGenなどの多くの有名な製品を熟知し、テストしました。しかし、これらの製品は以下の技術分野でいくつかの課題に直面しています:
- 顔の特徴の制限: 従来の技術では、明確で遮蔽されていない正面の写真をアップロードする必要があります。横顔や上向きの角度で撮影された写真は認識に失敗することが多く、認識できたとしても生成結果は大幅に損なわれます。
- 動きの制限: 初期の画像ベースのデジタルヒューマン技術では、体の動きが硬く、頭と口の動きしかなく、自然な体の動きが欠けていました。
- ピクセルの制限: 従来のリップシンク方法では、口の周りのピクセルが劣化し、口の周りがぼやけた出力になることが多く、クリエイティブな結果に悪影響を与えます。
- リズムの制限: 音声のスピーチ速度が速すぎると、デジタルヒューマンのリップシンクが乱れ、高頻度の口の動きに追従できなくなります。
OmniHuman-1の登場は、これらの技術的課題を成功裏に克服しました。マルチモーダルモーション条件付きハイブリッドトレーニング戦略を導入し、モデルが混合条件データ拡張の恩恵を受け、高品質データの不足を解決しました。OmniHuman-1は、ポートレート、半身、全身画像など、任意のアスペクト比の画像入力をサポートし、さまざまなシナリオで鮮やかで高品質な結果を提供します。
OmniHuman-1の革新的な価値
角度制限を排除しました。デジタルヒューマンを作成するために画像をアップロードする際、プラットフォームは一般的にユーザーに明確で遮蔽されていない正面の写真を提出するよう求めます。その理由は単純です:この技術の核心は顔の特徴を正確に認識することにあります。それが失敗すると、「顔を認識できません」というプロンプトが表示されます。したがって、以下のような写真は明らかに受け入れられません。横顔や上向きの角度は認識に失敗することが多く、運が良ければ45度の横顔が認識されることもありますが、生成結果は大幅に損なわれ、口の歪みなどの問題が一般的です。


では、OmniHuman-1の90度横顔と上向き角度でのパフォーマンスを見てみましょう:
両方の動画でのリップシンクはほぼ完璧で、幅広い自然な動きが伴います。これは強弱の違いではなく、可能と不可能の違いです。
OmniHuman-1は角度制限を排除し、映画やビデオ制作のキャラクターがカメラを直接向くことに限定されず、幅広い対話角度やショット構成を「アンロック」できるようにしました。さらに、改善された顔の特徴認識は、動物などの非人間の顔に対する許容度も向上させました。例えば、3Dスタイルの子羊が基本的なリップシンクと対話認識を実現し、日常の創作ニーズを満たすようになりました。
さらに、顔の特徴に対する許容度の向上は、以下の2Dアニメや水墨画スタイルの認識にも反映されています。他のモデルもこれらのスタイルで口の動きを生成できますが、完全性と体の動きのダイナミクスに関しては、OmniHuman-1が現在でも最高です。これは、画像ベースのデジタルヒューマンに関する次の問題につながります。
OmniHuman-1は、I2V(Image-to-Video)レベルでのダイナミックな視覚的パフォーマンスに優れています。孫悟空の例を見てみましょう:彼の顔認識は非常に正確で、話すときには全身と周囲の環境が自然で大きな動きをしています。頭の上下運動は体のリズムとシームレスに統合され、水の波も彼の動作と同期し、単一の画像からアニメーションビデオ生成を駆動しているかのようです。
音楽に関して、OmniHuman-1は特定の最適化を施しています。音楽の歌詞を直接認識するだけでなく、キャラクターの顔は幅広い感情を表示し、複数人の歌唱や楽器演奏をサポートします。
そのリップピクセルのパフォーマンスはさらに驚くべきものです。キャラクターの元の顔の特徴を保持するだけでなく、非常に高い明瞭度を実現しています。例えば、Fokのアニメーションと女性歌手のクローズアップディテールでは、生成された歯さえも非常に自然に再現されています。
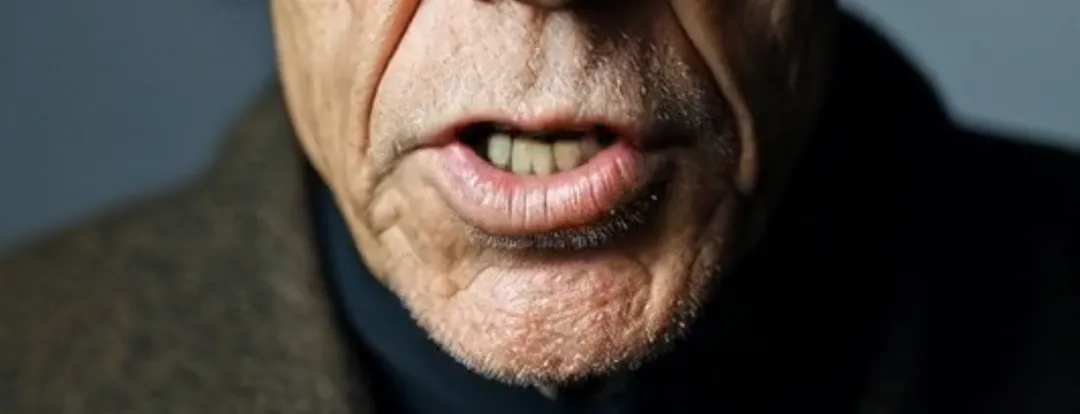
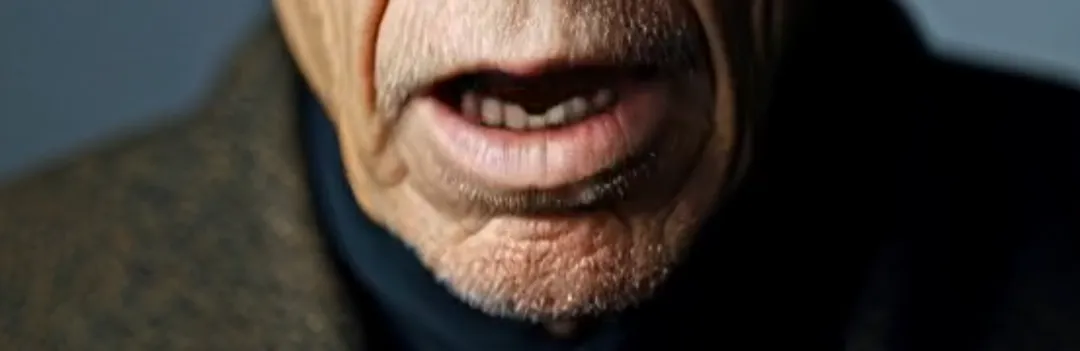



次はピクセル認識です。これはリップシンクを妨げる2つの要素、強い照明と長いひげに関連しています。前者は、強い光と影のコントラストを持つ画像がビデオ生成に失敗する原因となります。Runwayでは、「過度の光と影のコントラスト」というプロンプトが表示されます。例えば、サンプルビデオでは、車に座っている老人の顔に常に変化する影があります。OmniHuman-1以外では、ほとんど他のプラットフォームが唇を置き換えることに成功しません。長いひげは、口の周りがぼやける原因となることが多いですが、サンプルクリップで見られるように、OmniHuman-1はひげをほぼ完璧に再現し、ディテールの損失はありません。
印象的です。他に言葉はありません。
最後の課題は、話す速度が速すぎる問題です。経験のある人なら誰でも遭遇したことがあるでしょう:提供する音声のスピーチ速度が速すぎると、デジタルヒューマンのリップシンクは確実に乱れます。これは、アニメーションフレームレートが高頻度の口の動きの変化に追従するのに苦労し、ミスマッチが生じるためです。しかし、OmniHuman-1はこの問題も非常にうまく解決しました。スティーブ・ジョブズが非常に速いペースで話すセグメントでは、リップシンクにほとんど欠陥がありません。ラップミュージックでも問題ないはずです。
既存の問題と将来の展望
技術的に大きな進歩を遂げているにもかかわらず、OmniHuman-1にはまだ改善の余地があります。現在、OmniHuman-1は微調整機能を提供していません。例えば、キャラクターが話すとき、その動きの振幅が大きすぎることがあります。体の動きの振幅を微調整するオプションや、四肢の動きの選択肢を増やすことが提案されています。さらに、OmniHuman-1は現在、画像駆動のアニメーションのみをサポートしており、ビデオリップシンクはまだサポートされていません。この機能が早く導入されることが期待されます。生成されるコンテンツの現在の15秒の制限は短くはありませんが、まだ改善の余地があります。生成速度に関しては、内部テスト段階では、1つのクリップを生成するのに約15〜20分かかります。製品が正式にリリースされる際に、このプロセスが最適化され、より効率的になることが期待されます。
まとめ
強力な技術力と卓越したパフォーマンスにより、OmniHuman-1は間違いなく現在利用可能な最高のAIデジタルヒューマン製品です。顔の特徴の許容度、精度、美的魅力においてトップレベルのパフォーマンスを達成し、個々の機能において明確な優位性を持っています。そのリリースは、デジタルヒューマンとAIミュージックビデオの応用を大幅に促進し、映画やテレビ制作にさらなる可能性をもたらすことが期待されます。OmniHuman-1はAIデジタルヒューマン分野にゲームチェンジングな影響を与え、正式リリース時にさらなる驚きが待ち受けていることを期待しています。
本記事は、AITalkのブロガーHan Qingの内容を基にしています。特別な感謝を捧げます。