OmniHuman-1: Генерация видео с помощью ИИ от ByteDance
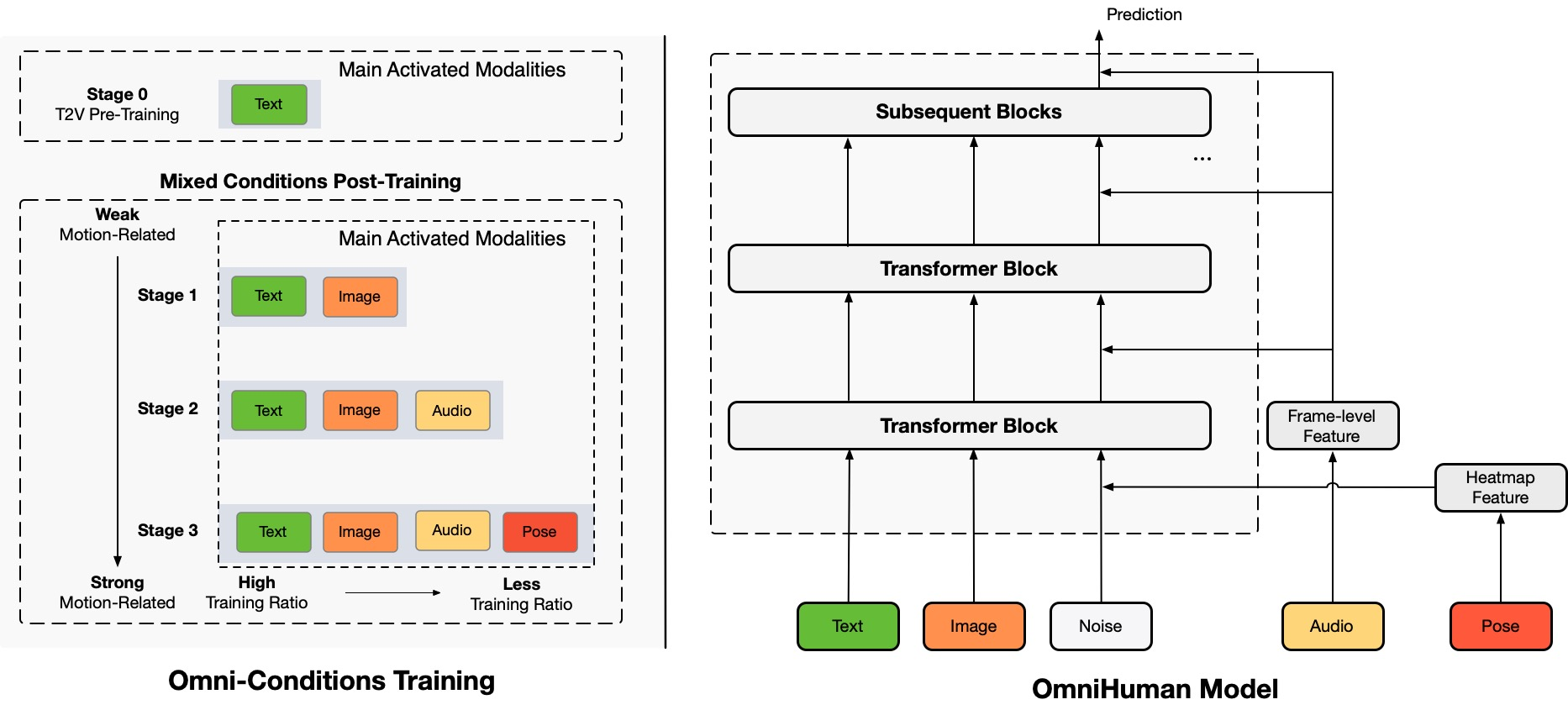
Architecture Overview
TL;DR:Мы предлагаем энд-ту-энд фреймворк для генерации человеческих видео с условием многомодальности, называемый OmniHuman, который может генерировать человеческие видео на основе одного человеческого изображения и сигналов движения (например, только аудио, только видео или комбинация аудио и видео). В OmniHuman мы вводим стратегию смешанного обучения с условием многомодальности движения, что позволяет модели использовать преимущества масштабируемости данных смешанного условия. Это решает проблему, с которой сталкивались предыдущие энд-ту-энд подходы из-за дефицита высококачественных данных. OmniHuman значительно превосходит существующие методы, генерируя чрезвычайно реалистичные человеческие видео на основе слабых сигнальных входов, особенно аудио. Он поддерживает входные изображения любого соотношения сторон, будь то портреты, полутела или полные тела, и обеспечивает более реалистичные и высококачественные результаты в различных сценариях.
Сгенерированные видео
OmniHuman поддерживает различные визуальные и аудио стили. Он может генерировать реалистичные человеческие видео в любом соотношении сторон и пропорциях тела (портрет, полутело, полное тело, все в одном), с реализмом, исходящим из всеобъемлющих аспектов, таких как движение, освещение и текстурные детали.
* sections.generatedVideos.note
Пение
OmniHuman может поддерживать различные музыкальные стили и множество поз тела и форм пения. Он может справляться с высокочастотными песнями и демонстрировать различные стили движения для различных типов музыки. Не забудьте выбрать лучшее качество видео. Качество сгенерированного видео также сильно зависит от качества опорного изображения.
Разговор
OmniHuman может поддерживать входы любого соотношения сторон в отношении речи. Он значительно улучшает обработку жестов, что является вызовом для существующих методов, и производит чрезвычайно реалистичные результаты. Аудио и изображения для некоторых тестовых случаев взяты из link1, link2, link3, link4.
Разнообразие
В отношении разнообразия входов OmniHuman поддерживает мультфильмы, искусственные объекты, животных и сложные позы, обеспечивая соответствие характеристик движения уникальным особенностям каждого стиля.
Больше примеров портретов
Здесь также включена секция, посвященная результатам в соотношении сторон портрета, которые получены из тестовых образцов в наборах данных CelebV-HQ.
Больше примеров полутела с руками
Здесь также предоставляются дополнительные примеры, демонстрирующие движения жестов. Некоторые входные изображения и аудио взяты из TED, Pexels и AIGC.
Совместимость с видео-драйвером
Благодаря характеристикам смешанного обучения с условием OmniHuman, он может поддерживать не только аудио-драйвер, но и видео-драйвер для имитации конкретных видео действий, а также комбинированный аудио и видео-драйвер (случай link) для управления конкретными частями тела, как недавние методы. Ниже мы демонстрируем эти возможности.
Этические опасения
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Если вы находите этот проект полезным для вашего исследования, вы можете процитировать нас и ознакомиться с нашими другими связанными работами:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}