
OmniHuman-1的惊艳表现
</p> 在数字人和AI唇语同步技术领域,AI.TALK团队凭借深厚的行业积累和丰富的实践经验,创造了约300个数字人。他们几乎尝试了市场上所有开源和闭源的数字人技术,积累了大量的实践经验。在参与OmniHuman-1的内测后,团队对这款产品给予了极高的评价,
认为它是目前最好的AI数字人产品——没有之一。
这是夸大其词吗?让我们看看这个例子:

<iframe
style="width: 100%; height: auto; aspect-ratio: 16/9;" src="https://cdn.omnihuman1.org/video/0b2edmabwaaamaapygfymbtvag6ddmnqagya.f10002.mp4"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
</iframe>OmniHuman-1的强大之处在于,它能够完美实现数字人在侧脸视角下的唇语同步,自动识别音乐中的歌词,并使基于图像的数字人能够自然摇摆并与乐器互动。
现在,让我们看看以下片段:
它的嘴部清晰度极高,即使在麦克风遮挡或复杂光线等挑战性条件下,唇语同步仍然准确。此外,角色能够随着音乐展现出丰富的面部表情。这些能力让团队惊叹不已。
突破技术难题
该团队成立于2023年初,期间他们熟悉并测试了许多知名产品,如D-ID和HeyGen。然而,这些产品在以下技术领域仍面临一些挑战:
- 面部特征限制:传统技术需要上传清晰、无遮挡的正面照片。侧面或仰角拍摄的照片往往会导致识别失败。即使勉强识别,生成的结果也会大打折扣。
- 动态限制:早期的基于图像的数字人技术中,身体动作僵硬,只有头部和嘴部动作,缺乏自然的肢体动态。
- 像素限制:传统的唇语同步方法往往会导致嘴部周围的像素退化,导致嘴部模糊,影响创作效果。
- 节奏限制:当音频语速过快时,数字人的唇语同步可能会变得混乱,难以匹配高频的嘴部动作。
OmniHuman-1的出现成功克服了这些技术难题。它引入了多模态运动条件混合训练策略,使模型能够从混合条件数据扩展中受益,并解决了高质量数据稀缺的问题。OmniHuman-1支持任何比例的图像输入,无论是肖像、半身还是全身图像,都能在各种场景中提供生动且高质量的结果。
OmniHuman-1的创新价值
它消除了角度限制。当我们上传图像创建数字人时,平台通常要求用户提交清晰、无遮挡的正面照片。原因很简单:该技术的核心依赖于准确识别面部特征。如果失败,会出现“无法识别人脸”的提示。因此,像下面这样的照片肯定是不可接受的,因为侧面或仰角往往会导致识别失败。有时,运气好的话,45度侧面可能会被识别,但生成的结果会大打折扣,常见的问题如嘴部扭曲。


现在,让我们看看OmniHuman-1在90度侧面和仰角下的表现:
两个视频中的唇语同步几乎完美,伴随着丰富的自然动作。请注意,这不是强弱之分,而是可能与不可能的区别。
OmniHuman-1消除了角度限制,使影视制作中的角色能够“解锁”广泛的对话角度和镜头构图,不再局限于直接面对镜头。此外,改进的面部特征识别也增强了对非人脸的容忍度,例如动物。例如,3D风格的小羊现在可以实现基本的唇语同步和对话识别,满足日常创作需求。
此外,对面部特征的容忍度提高也体现在对不同风格的识别上,如下面提到的2D动漫和水墨风格。虽然其他模型也能在这些风格中生成唇部动作,但在完整性和身体动作的动态性方面,OmniHuman-1仍然是目前最好的。这引出了关于基于图像的数字人的下一个问题。
OmniHuman-1在I2V(图像到视频)级别的动态视觉表现上表现出色。以孙悟空为例:他的面部识别非常准确,当他说话时,整个身体和周围环境都处于自然的高幅度运动中。头部的上下运动与身体的节奏无缝结合,甚至水波也同步于他的动作,仿佛从单张图像驱动动画视频生成。
在音乐方面,OmniHuman-1进行了针对性优化。除了直接识别音乐中的歌词外,角色的面部还能展现出丰富的情感,并支持多人演唱和乐器表演。
它的唇部像素表现更加惊人。它不仅保留了角色的原始面部特征,还实现了极高的清晰度。例如,在Fok动画和一位女歌手的特写细节中,甚至生成的牙齿也极其自然地再现。
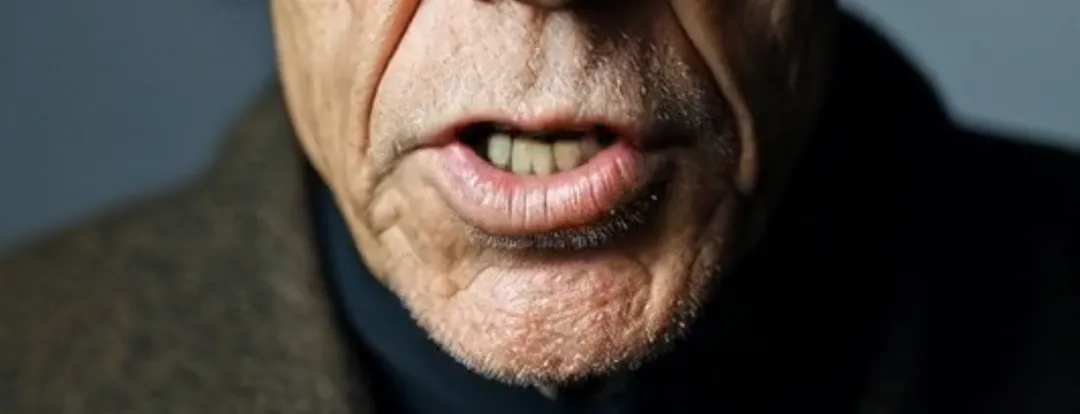
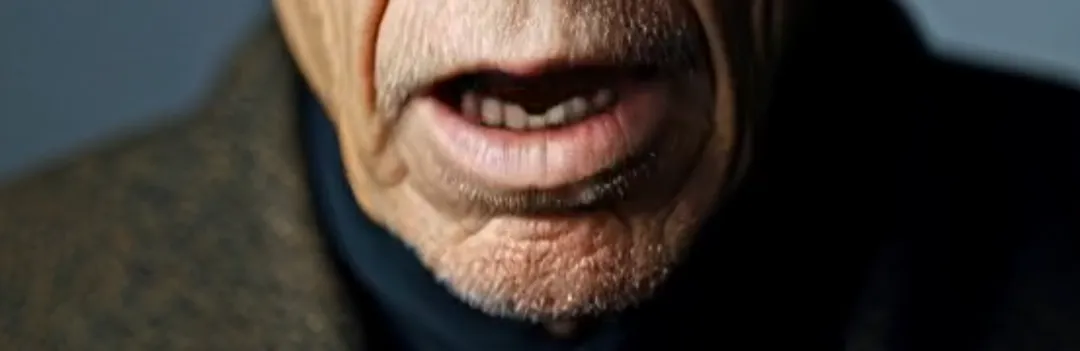



接下来是像素识别,这涉及到两个经常干扰唇语同步的元素:强光和长胡子。前者会导致光影对比强烈的图像无法生成视频。在Runway中,会提示“光影对比过度”。例如,在一个样本视频中,一位坐在车里的老人脸上不断变化的阴影。除了OmniHuman-1,几乎没有任何其他平台能够成功替换嘴唇。长胡子则往往会导致嘴部周围的模糊。然而,正如样本片段所示,OmniHuman-1几乎可以完美地再现胡子,没有任何细节损失。
令人印象深刻,没有其他词语可以形容。
最后的挑战是语速过快的问题。任何有经验的人都遇到过这种情况:当你提供的音频语速过快时,数字人的唇语同步肯定会变得混乱。这是因为动画帧率难以匹配唇部动作的高频变化,导致不匹配。然而,OmniHuman-1也很好地解决了这个问题。在史蒂夫·乔布斯以极快语速讲话的片段中,唇语同步几乎没有瑕疵。即使是说唱音乐,也不应该是个问题。
现存问题与未来展望
尽管在技术上取得了显著进步,OmniHuman-1仍有改进空间。目前,OmniHuman-1不提供任何微调功能。例如,当角色说话时,他们的动作幅度可能过大。建议增加对身体动作幅度的微调选项,并提供更多肢体动作的选择。此外,OmniHuman-1目前仅支持图像驱动的动画,尚不支持视频唇语同步。希望这一功能能尽快推出。目前生成内容的15秒限制并不短,但仍有改进空间。在生成速度方面,在内测阶段,生成单个片段大约需要15-20分钟。希望在产品正式发布时能够优化并提高效率。
总结
凭借强大的技术能力和出色的表现,OmniHuman-1无疑是目前最好的AI数字人产品。它在面部特征容忍度、精度和美观度上达到了顶级水平,在个别功能上具有明显优势。它的推出预计将显著推动数字人和AI音乐视频的应用,并为影视制作带来更多可能性。OmniHuman-1对AI数字人领域产生了颠覆性影响,我们期待它在正式发布时带来更多惊喜。
本文改编自AITalk博主韩青的内容,特别感谢。