OmniHuman-1: AI Video Generation by Bytedance
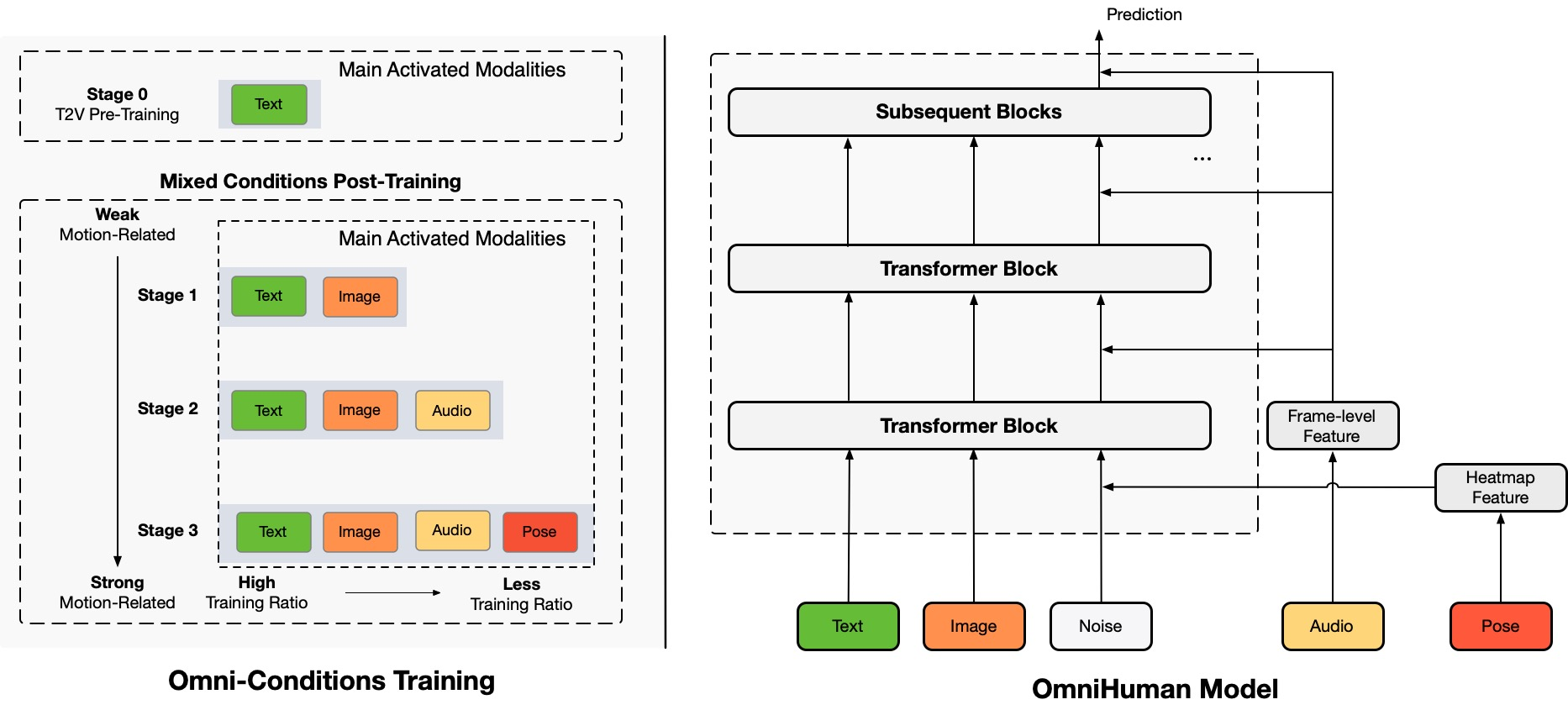
Architecture Overview
TL;DR:Kami mengusulkan kerangka pembuatan video manusia berkondisi multimodalitas end-to-end yang disebut OmniHuman, yang dapat menghasilkan video manusia berdasarkan satu gambar manusia dan sinyal gerak (misalnya, hanya audio, hanya video, atau kombinasi audio dan video). Di OmniHuman, kami memperkenalkan strategi pelatihan campuran kondisi gerak multimodalitas, yang memungkinkan model untuk memanfaatkan skala data kondisi campuran. Ini mengatasi masalah yang dihadapi oleh pendekatan end-to-end sebelumnya karena kekurangan data berkualitas tinggi. OmniHuman secara signifikan mengungguli metode yang ada, menghasilkan video manusia yang sangat realistis berdasarkan input sinyal lemah, terutama audio. Ini mendukung input gambar dengan rasio aspek apa pun, apakah itu potret, setengah badan, atau gambar badan penuh, memberikan hasil yang lebih hidup dan berkualitas tinggi di berbagai skenario.
Generated Videos
OmniHuman mendukung berbagai gaya visual dan audio. Ini dapat menghasilkan video manusia realistis dengan rasio aspek apa pun dan proporsi badan (potret, setengah badan, badan penuh semuanya dalam satu), dengan realisme yang berasal dari aspek komprehensif termasuk gerak, pencahayaan, dan detail tekstur.
* Perhatikan bahwa untuk menghasilkan semua hasil di halaman ini, hanya satu gambar dan audio yang diperlukan, kecuali untuk demo yang menampilkan sinyal penggerak video dan kombinasi. Untuk tujuan tata letak yang bersih, kami telah menghilangkan tampilan gambar referensi, yang pada kebanyakan kasus adalah frame pertama dari video yang dihasilkan. Jika Anda membutuhkan perbandingan atau informasi lebih lanjut, jangan ragu untuk menghubungi kami.
Singing
OmniHuman dapat mendukung berbagai gaya musik dan mengakomodasi berbagai pose tubuh dan bentuk nyanyian. Ini dapat menangani lagu dengan nada tinggi dan menampilkan berbagai gaya gerak untuk jenis musik yang berbeda. Harap pilih kualitas video tertinggi. Kualitas video yang dihasilkan juga sangat bergantung pada kualitas gambar referensi.
Talking
OmniHuman dapat mendukung input dengan rasio aspek apa pun dalam hal pidato. Ini secara signifikan memperbaiki penanganan gestur, yang merupakan tantangan bagi metode yang ada, dan menghasilkan hasil yang sangat realistis. Audio dan gambar untuk beberapa kasus uji diambil dari link1, link2, link3, link4.
Diversity
Dalam hal keanekaragaman input, OmniHuman mendukung kartun, objek buatan, hewan, dan pose tantangan, memastikan karakteristik gerak cocok dengan fitur unik setiap gaya.
More Portrait Cases
Di sini, kami juga termasuk bagian yang didedikasikan untuk hasil rasio aspek potret, yang diambil dari sampel uji dalam dataset CelebV-HQ.
More Halfbody Cases with Hands
Di sini, kami juga memberikan contoh tambahan yang secara khusus menampilkan gerakan gestur. Beberapa gambar dan audio input berasal dari TED, Pexels dan AIGC.
Compatibility with Video Driving
Karena karakteristik pelatihan kondisi campuran OmniHuman, ini dapat mendukung tidak hanya penggerak audio tetapi juga penggerak video untuk meniru tindakan video tertentu, serta penggerak audio dan video gabungan (kasus dari link) untuk mengontrol bagian tubuh tertentu seperti metode terkini. Di bawah ini, kami mendemonstrasikan kemampuan ini.
Ethics Concerns
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Jika Anda menemukan proyek ini berguna untuk penelitian Anda, Anda dapat mengutip kami dan memeriksa karya terkait lainnya kami:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}