OmniHuman-1: ByteDanceによるAIビデオ生成
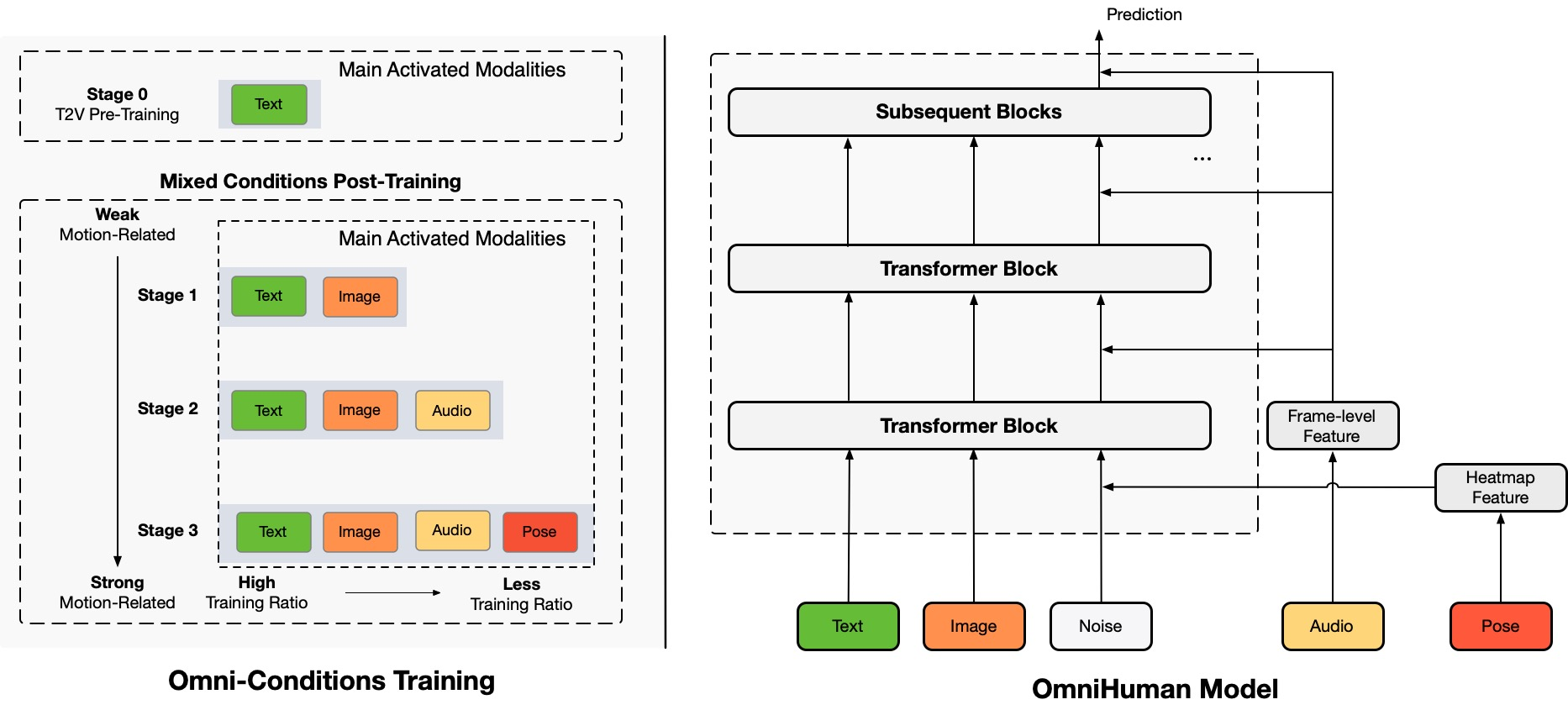
Architecture Overview
TL;DR:私たちは、OmniHumanと呼ばれるエンドツーエンドの多様性条件付き人間ビデオ生成フレームワークを提案しています。これは、単一の人間の画像と動きの信号(例えば、オーディオのみ、ビデオのみ、またはオーディオとビデオの組み合わせ)に基づいて人間のビデオを生成することができます。OmniHumanでは、混合条件付き動きの条件付け混合トレーニング戦略を導入しており、これによりモデルは混合条件付けデータのスケーリングの恩恵を受けることができます。これにより、高品質なデータの希少さによる以前のエンドツーエンドアプローチの問題が解決されます。OmniHumanは、特にオーディオのような弱い信号入力に基づいて、既存の方法を大幅に上回る非常にリアルな人間のビデオを生成します。どのようなアスペクト比の画像入力もサポートし、ポートレート、ハーフボディ、フルボディのどれでも、さまざまなシナリオでよりリアルで高品質な結果を提供します。
生成されたビデオ
OmniHumanは、さまざまな視覚的および音響的なスタイルをサポートしています。どのようなアスペクト比や体の比率(ポートレート、ハーフボディ、フルボディ、すべて一つに)でもリアルな人間のビデオを生成することができ、動き、照明、テクスチャの詳細から得られるリアリズムを備えています。
* sections.generatedVideos.note
歌
OmniHumanは、さまざまな音楽スタイルや複数の体のポーズ、歌い方をサポートします。高音の歌も対応し、異なる音楽タイプに対して異なる動きのスタイルを表示することができます。最高のビデオ品質を選択することを忘れないでください。生成されたビデオの品質も、参照画像の品質に大きく依存します。
話す
OmniHumanは、話すことに関してどのようなアスペクト比の入力もサポートします。ジェスチャーの取り扱いを大幅に改善し、既存の方法では課題となるリアルな結果を生成します。いくつかのテストケースのオーディオと画像は、link1、link2、link3、link4から取得されています。
多様性
入力の多様性に関して、OmniHumanはカートゥーン、人工物体、動物、挑戦的なポーズをサポートし、各スタイルのユニークな特徴に動きの特性が一致するようにします。
さらにポートレートケース
ここでは、CelebV-HQデータセットのテストサンプルから得られたポートレートアスペクト比の結果に焦点を当てたセクションも含まれています。
さらにハーフボディケース(手を含む)
ここでは、特にジェスチャーの動きを示す追加の例も提供しています。いくつかの入力画像とオーディオは、TED、Pexels、AIGCから取得されています。
ビデオドライブとの互換性
OmniHumanの混合条件付けトレーニングの特性により、オーディオドライブだけでなく、特定のビデオアクションを模倣するためのビデオドライブや、最近の方法のように体の特定の部分(例えば、口と手)を制御するためのオーディオとビデオの組み合わせドライブ(linkのケース)もサポートしています。以下に、これらの機能を示します。
倫理的懸念
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
このプロジェクトがあなたの研究に役立つ場合は、私たちを引用し、他の関連する作品もご覧ください:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}