OmniHuman-1: AI Video Generation by Bytedance
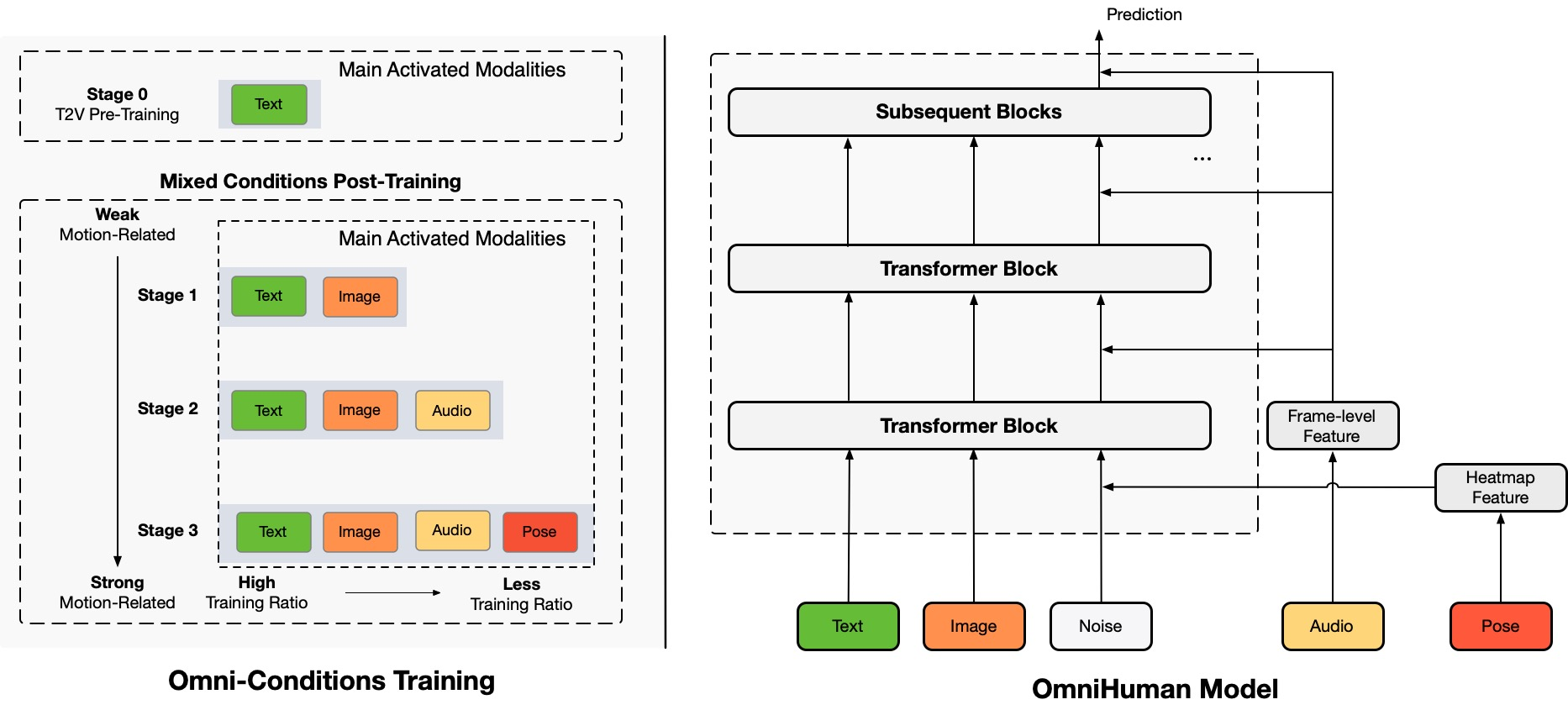
Architecture Overview
TL;DR:Proponujemy ramy do generowania wideo z ludźmi w trybie multimodalnym od końca do końca o nazwie OmniHuman, które mogą generować filmy z ludźmi na podstawie pojedynczego obrazu człowieka i sygnałów ruchu (np. tylko audio, tylko wideo lub kombinacja audio i wideo). W OmniHuman wprowadzamy strategię treningu mieszanego warunkowania ruchu wielomodalnego, która pozwala modelowi korzystać ze skalowalności danych warunkowania mieszanego. To przekracza problem, z którym boryły się poprzednie podejścia od końca do końca z powodu niedostatku wysokiej jakości danych. OmniHuman znacznie przewyższa istniejące metody, generując ekstremalnie realistyczne filmy z ludźmi na podstawie słabych sygnałów wejściowych, zwłaszcza audio. Obsługuje on również wszystkie proporcje obrazu, czy to portrety, półpostaci czy postaci w całości, i zapewnia bardziej realistyczne i wysokiej jakości wyniki w różnych scenariuszach.
Wygenerowane filmy
OmniHuman obsługuje różne style wizualne i audio. Może generować realistyczne filmy z ludźmi w dowolnej proporcji i proporcji ciała (portret, półpostać, pełna postać, wszystko w jednym), z realizmem wynikającym z całościowych aspektów takich jak ruch, oświetlenie i tekstura detali.
* sections.generatedVideos.note
Śpiewanie
OmniHuman może obsługiwać różne style muzyczne i dostosowywać się do wielu pozycji ciała i form śpiewu. Może radzić sobie z piosenkami o wysokim tonie i pokazywać różne style ruchu dla różnych typów muzyki. Pamiętaj, aby wybrać najwyższą jakość wideo. Jakość wygenerowanego wideo jest również w dużej mierze uzależniona od jakości obrazu referencyjnego.
Rozmowa
OmniHuman może obsługiwać wejścia w dowolnej proporcji w zakresie mowy. Znacznie poprawia obsługę gestów, co stanowi wyzwanie dla istniejących metod, i produkuje ekstremalnie realistyczne wyniki. Audio i obrazy dla niektórych przypadków testowych pochodzą z link1, link2, link3, link4.
Różnorodność
Pod względem różnorodności wejścia OmniHuman obsługuje kreskówki, sztuczne obiekty, zwierzęta i trudne pozy, zapewniając, że cechy ruchu są zgodne z unikalnymi cechami każdego stylu.
Więcej przypadków portretowych
Tutaj zawieramy również sekcję poświęconą wynikom w proporcji portretu, które pochodzą z próbek testowych w zestawach danych CelebV-HQ.
Więcej przypadków półpostaci z rękami
Tutaj dostarczamy również dodatkowe przykłady, które pokazują specyficznie ruchy gestów. Niektóre obrazy i dźwięki wejściowe pochodzą z TED, Pexels i AIGC.
Zgodność z napędem wideo
Dzięki cechom treningu warunkowania mieszanego OmniHuman może on nie tylko obsługiwać napęd audio, ale także napęd wideo, aby naśladować specyficzne akcje wideo, a także połączony napęd audio i wideo (przypadek z linku), aby kontrolować określone części ciała, jak ostatnie metody. Poniżej prezentujemy te możliwości.
Etyczne zastrzeżenia
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Jeśli ten projekt jest przydatny w Twojej pracy badawczej, możesz nas cytować i sprawdzić nasze inne powiązane prace:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}