OmniHuman-1: AI Video Generation by Bytedance
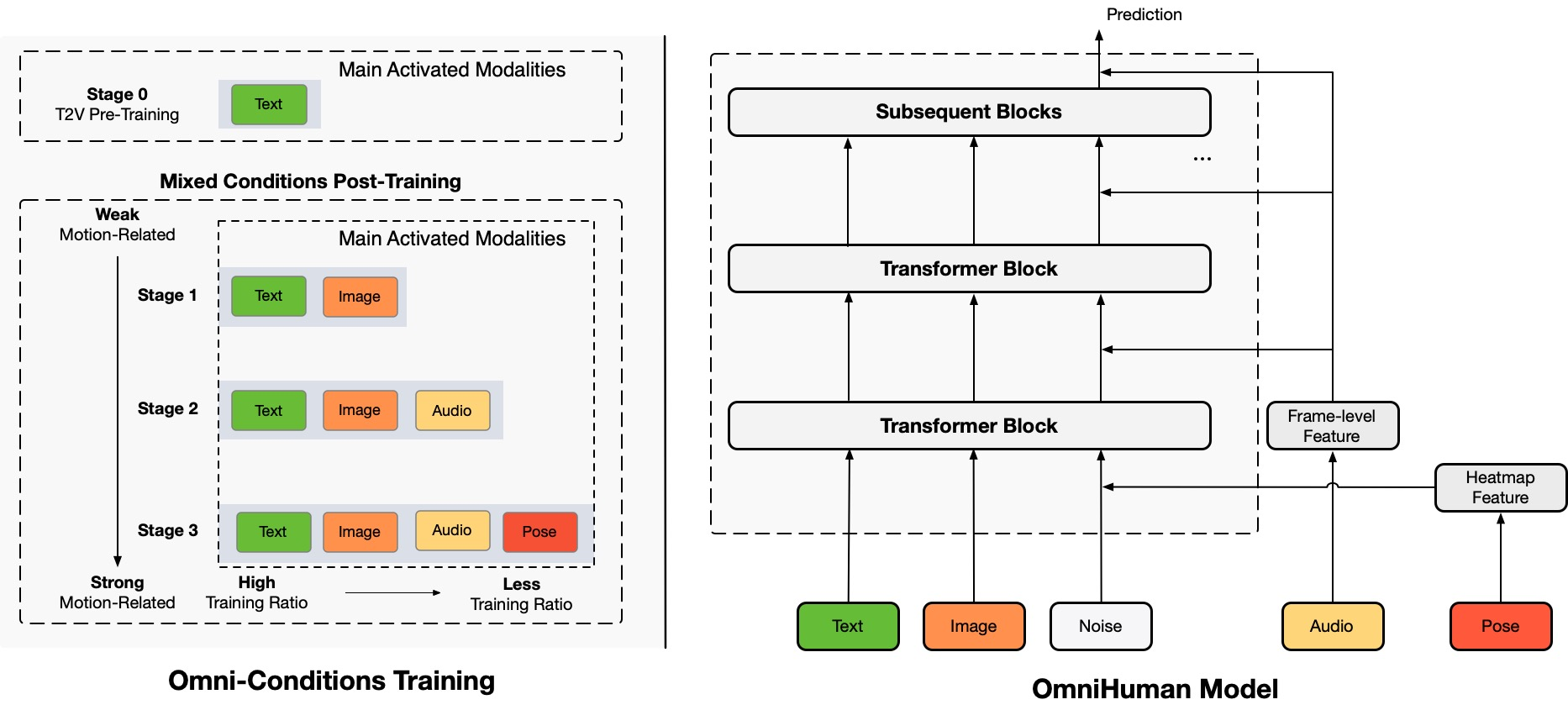
Architecture Overview
TL;DR:OmniHuman adlı uçtan uca çok modlu insan videosu üretim çerçevesini öneriyoruz. Bu çerçeve, tek bir insan görüntüsü ve hareket sinyalleri (örneğin, yalnızca ses, yalnızca video veya ses ve video kombinasyonu) kullanarak insan videosu üretebilir. OmniHuman'da, karma koşullandırma hareketi çok modlu koşullandırma eğitim stratejisini tanıttık, bu da modelin karma koşullandırma verilerinin ölçeklenebilirliğinden faydalanmasını sağlar. Bu, önceki uçtan uca yaklaşımların yüksek kaliteli veri yetersizliği nedeniyle karşılaştığı sorunu çözer. OmniHuman, özellikle ses gibi zayıf sinyal girdilerinden insan videosu üretme konusunda önemli ölçüde mevcut yöntemleri aşar ve zayıf sinyal girdilerinden insan videosu üretir. Tüm görüntü girişlerini destekler, resimler portre, yarı vücut veya tam vücut olabilir ve çeşitli senaryolarda daha gerçekçi ve yüksek kaliteli sonuçlar sunar.
Üretilen Videolar
OmniHuman, çeşitli görsel ve ses stilini destekler. Herhangi bir en-boy oranında ve vücut oranında (portre, yarı vücut, tam vücut, hepsi bir arada) gerçekçi insan videosu üretebilir, gerçekçiliği hareket, aydınlatma ve dokusu detaylarından kaynaklanır.
* sections.generatedVideos.note
Şarkı Söyleme
OmniHuman, çeşitli müzik stillerini ve çoklu vücut pozlarını ve şarkı söyleme biçimlerini destekleyebilir. Yüksek perdeli şarkıları yönetebilir ve farklı müzik türleri için farklı hareket stillerini gösterebilir. En yüksek video kalitesini seçmeyi unutmayın. Üretilen videonun kalitesi de referans görüntüsünün kalitesine çok bağlıdır.
Konuşma
OmniHuman, konuşma açısından herhangi bir en-boy oranını destekleyebilir. Mevcut yöntemler için bir zorluk olan işaretlerin işlenmesini önemli ölçüde iyileştirir ve son derece gerçekçi sonuçlar üretir. Bazı test senaryoları için ses ve görüntüler link1, link2, link3, link4'ten gelmektedir.
Çeşitlilik
Giriş çeşitliliği açısından OmniHuman, çizgi filmler, yapay nesneler, hayvanlar ve zor pozları destekler ve her stilin benzersiz özellikleriyle hareket özelliklerinin uyumlu olmasını sağlar.
Daha Fazla Portre Örneği
Burada, CelebV-HQ veri kümelerindeki test örneklerinden türetilen portre en-boy oranı sonuçlarına adanmış bir bölüm de dahil ediyoruz.
Daha Fazla Yarı Vücut Örneği
Burada, özellikle işaret hareketlerini gösteren ek örnekler de sunuyoruz. Bazı giriş görüntüleri ve sesler TED, Pexels ve AIGC'den gelmektedir.
Video Sürücüsüyle Uyumluluk
OmniHuman'ın karma koşullandırma eğitim özellikleri sayesinde, yalnızca ses sürücüsünü değil, aynı zamanda belirli video eylemlerini taklit etmek için video sürücüsünü de destekleyebilir ve ses ve video sürücüsünün kombinasyonunu (link durumundaki vaka) belirli vücut parçalarını kontrol etmek için kullanabilir. Aşağıda bu yetenekleri gösteriyoruz.
Etik Endişeler
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is fromVASA-1, and some test audios are fromVASA-1,Loopy,CyberHost.
BibTeX
Bu proje araştırmanız için yararlı bulursanız, bizi atıfta bulunabilir ve diğer ilgili çalışmalarımızı inceleyebilirsiniz:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of
One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang
and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar
with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang,
Jiaqi and Lin, Gaojie and Zhong, Tianyun and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar
Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang,
Chao and Zhong, Tianyun and Yang, Jiaqi and
Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}