
Performa Menakjubkan dari OmniHuman-1
</p> Di bidang digital human dan teknologi AI lip-sync, tim AI.TALK, dengan memanfaatkan keahlian industri yang mendalam dan pengalaman praktis yang luas, telah menciptakan sekitar 300 digital human. Mereka telah mencoba hampir semua teknologi digital human open-source dan proprietary yang tersedia di pasar, mengumpulkan banyak pengalaman langsung. Setelah berpartisipasi dalam pengujian beta OmniHuman-1, tim memberikan pujian yang sangat tinggi pada produk ini,
menganggapnya sebagai produk AI digital human terbaik yang tersedia saat ini—tanpa tanding.
Apakah ini berlebihan? Mari kita lihat contoh ini:

<iframe
style="width: 100%; height: auto; aspect-ratio: 16/9;" src="https://cdn.omnihuman1.org/video/0b2edmabwaaamaapygfymbtvag6ddmnqagya.f10002.mp4"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
</iframe>Kekuatan OmniHuman-1 terletak pada kemampuannya untuk mencapai lip-sync yang sempurna untuk digital human dalam tampilan profil, secara otomatis mengenali lirik dalam musik, dan memungkinkan digital human berbasis gambar untuk bergerak secara alami dan berinteraksi dengan instrumen musik.
Sekarang, mari kita lihat segmen berikut:
Kejelasan mulutnya sangat tinggi, dan bahkan dalam kondisi yang menantang seperti obstruksi mikrofon atau pencahayaan yang kompleks, lip-sync tetap akurat. Selain itu, karakter dapat menampilkan berbagai emosi wajah yang selaras dengan musik. Kemampuan ini membuat tim terkesima.
Terobosan dalam Mengatasi Tantangan Teknis
Tim ini didirikan pada awal tahun 2023, dan sepanjang perjalanan, mereka telah mengenal dan menguji banyak produk terkenal, seperti D-ID dan HeyGen. Namun, produk-produk ini masih menghadapi beberapa tantangan dalam bidang teknis berikut:
- Batasan Fitur Wajah: Teknologi tradisional memerlukan pengunggahan foto frontal individu yang jelas dan tidak terhalang. Foto yang diambil dari samping atau sudut ke atas sering mengakibatkan kegagalan pengenalan. Bahkan jika pengenalan berhasil, hasil yang dihasilkan akan sangat terganggu.
- Batasan Dinamis: Dalam teknologi digital human berbasis gambar awal, gerakan tubuh kaku, hanya gerakan kepala dan mulut, tanpa dinamika tubuh yang alami.
- Batasan Pixel: Metode lip-sync konvensional sering menyebabkan degradasi pixel di sekitar mulut, menghasilkan output yang buram di sekitar mulut, yang berdampak negatif pada hasil kreatif.
- Batasan Ritme: Ketika kecepatan bicara audio terlalu cepat, lip-sync digital human bisa menjadi kacau, sulit untuk mencocokkan gerakan mulut frekuensi tinggi.
Munculnya OmniHuman-1 telah berhasil mengatasi tantangan teknis ini. Ini memperkenalkan strategi pelatihan hibrida multimodal yang dikondisikan gerakan, memungkinkan model untuk mendapatkan manfaat dari ekspansi data kondisi campuran dan mengatasi kelangkaan data berkualitas tinggi. OmniHuman-1 mendukung input gambar dengan rasio aspek apa pun, baik gambar potret, setengah badan, atau gambar seluruh badan, memberikan hasil yang hidup dan berkualitas tinggi di berbagai skenario.
Nilai Inovatif OmniHuman-1
Ini menghilangkan batasan sudut. Ketika kita mengunggah gambar untuk membuat digital human, platform umumnya mengharuskan pengguna untuk mengirimkan foto frontal individu yang jelas dan tidak terhalang. Alasannya sederhana: inti dari teknologi ini bergantung pada pengenalan fitur wajah yang akurat. Jika gagal, pesan seperti "Tidak dapat mengenali wajah" akan muncul. Oleh karena itu, foto seperti di bawah ini pasti tidak dapat diterima, karena sudut samping atau ke atas sering mengakibatkan kegagalan pengenalan. Terkadang, dengan keberuntungan, sudut samping 45 derajat mungkin bisa dikenali, tetapi hasil yang dihasilkan akan sangat terganggu, dengan masalah seperti mulut yang terdistorsi menjadi hal biasa.


Sekarang, mari kita lihat performa OmniHuman-1 dengan profil samping 90 derajat dan sudut ke atas:
Lip-sync dalam kedua video hampir sempurna, disertai dengan berbagai gerakan alami. Perhatikan bahwa ini bukan perbedaan antara performa kuat dan lemah—ini adalah perbedaan antara apa yang mungkin dan apa yang tidak mungkin.
OmniHuman-1 menghilangkan batasan sudut, memungkinkan karakter dalam produksi film dan video untuk "membuka" berbagai sudut dialog dan komposisi shot, tidak lagi terbatas pada menghadap kamera secara langsung. Selain itu, peningkatan pengenalan fitur wajah juga meningkatkan toleransi untuk wajah non-manusia, seperti hewan. Misalnya, domba gaya 3D sekarang dapat mencapai lip-sync dasar dan pengenalan dialog, memenuhi kebutuhan kreasi sehari-hari.
Selain itu, peningkatan toleransi untuk fitur wajah juga tercermin dalam pengenalan berbagai gaya, seperti gaya anime 2D dan gaya tinta yang disebutkan di bawah ini. Meskipun model lain juga dapat menghasilkan gerakan bibir dalam gaya ini, dalam hal kelengkapan dan dinamika gerakan tubuh, OmniHuman-1 masih yang terbaik saat ini. Ini mengarah pada masalah berikutnya mengenai digital human berbasis gambar.
OmniHuman-1 unggul dalam performa visual dinamis di tingkat I2V (Image-to-Video). Ambil contoh Sun Wukong (Raja Kera): Pengenalan wajahnya sangat akurat, dan ketika dia berbicara, seluruh tubuh dan lingkungan sekitarnya bergerak dengan amplitudo tinggi yang alami. Gerakan kepala naik turunnya terintegrasi dengan ritme tubuhnya, dan bahkan gelombang air selaras dengan tindakannya, seolah-olah menggerakkan generasi video animasi dari satu gambar.
Dalam hal musik, OmniHuman-1 telah mengalami optimasi yang ditargetkan. Selain langsung mengenali lirik dalam musik, wajah karakter juga dapat menampilkan berbagai emosi dan mendukung nyanyian multi-orang dan pertunjukan instrumen.
Performa pixel bibirnya bahkan lebih menakjubkan. Ini tidak hanya mempertahankan fitur wajah asli karakter tetapi juga mencapai tingkat kejelasan yang sangat tinggi. Misalnya, dalam detail close-up animasi Fok dan seorang penyanyi wanita, bahkan gigi yang dihasilkan direproduksi dengan sangat alami.
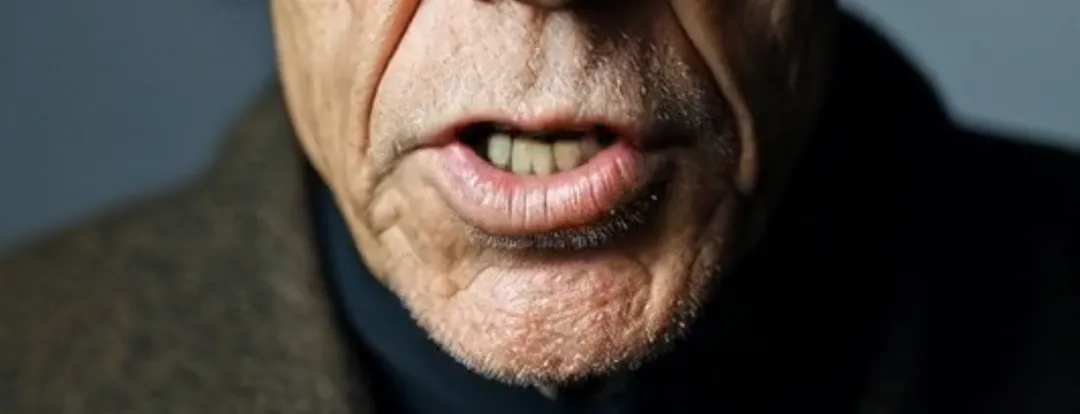
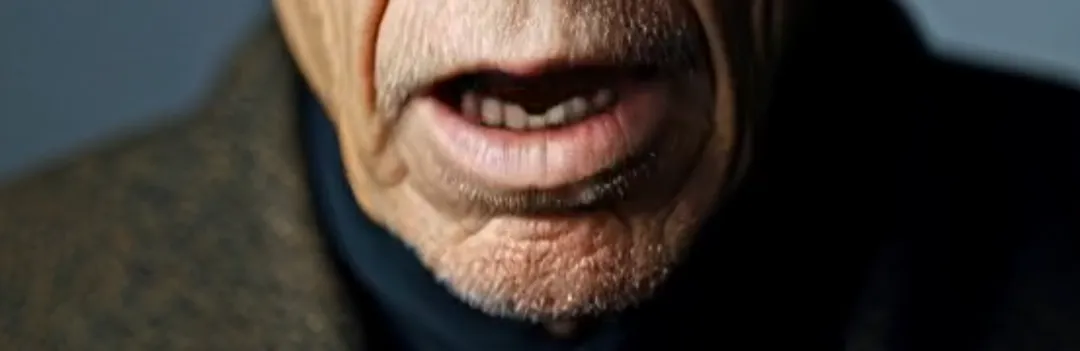



Selanjutnya adalah pengenalan pixel, yang melibatkan dua elemen yang sering mengganggu lip-sync: pencahayaan kuat dan janggut panjang. Yang pertama dapat menyebabkan gambar dengan kontras cahaya dan bayangan yang intens gagal dalam generasi video. Di Runway, itu akan memunculkan pesan “kontras cahaya dan bayangan yang berlebihan.” Misalnya, dalam sampel video, seorang lansia yang duduk di mobil memiliki bayangan yang terus berubah di wajahnya. Selain OmniHuman-1, hampir tidak ada platform lain yang dapat berhasil mengganti bibir. Janggut panjang, di sisi lain, sering menyebabkan keburaman di sekitar mulut. Namun, seperti yang terlihat dalam klip sampel, OmniHuman-1 hampir sempurna dalam mereproduksi janggut tanpa kehilangan detail.
Mengagumkan, tidak ada kata lain untuk menggambarkannya.
Tantangan terakhir adalah masalah berbicara terlalu cepat. Siapa pun yang berpengalaman pasti pernah mengalami ini: ketika kecepatan bicara dalam audio yang Anda berikan terlalu cepat, lip-sync digital human pasti akan menjadi kacau. Ini karena frame rate animasi kesulitan mencocokkan perubahan frekuensi tinggi dalam gerakan bibir, menghasilkan ketidakcocokan. Namun, OmniHuman-1 juga telah mengatasi masalah ini dengan sangat baik. Dalam segmen dengan Steve Jobs berbicara dengan kecepatan yang sangat cepat, hampir tidak ada cacat dalam lip-sync. Bahkan untuk musik rap, seharusnya tidak menjadi masalah.
Masalah yang Ada dan Masa Depan
Meskipun telah mencapai kemajuan teknologi yang signifikan, OmniHuman-1 masih memiliki area untuk perbaikan. Saat ini, OmniHuman-1 tidak menawarkan fungsi fine-tuning apa pun. Misalnya, ketika karakter berbicara, amplitudo gerakan mereka bisa terlalu besar. Disarankan untuk menambahkan opsi untuk fine-tuning amplitudo gerakan tubuh dan memberikan lebih banyak pilihan untuk tindakan anggota tubuh. Selain itu, OmniHuman-1 saat ini hanya mendukung animasi yang digerakkan oleh gambar dan belum mendukung lip-sync video. Diharapkan fitur ini akan segera diperkenalkan. Batasan saat ini dari 15 detik untuk konten yang dihasilkan tidak pendek, tetapi masih ada ruang untuk perbaikan. Dalam hal kecepatan generasi, selama fase pengujian internal, dibutuhkan sekitar 15-20 menit untuk menghasilkan satu klip. Diharapkan proses ini dapat dioptimalkan dan dibuat lebih efisien ketika produk diluncurkan secara resmi.
Ringkasan
Dengan kemampuan teknis yang kuat dan performa yang luar biasa, OmniHuman-1 tidak diragukan lagi adalah produk AI digital human terbaik yang tersedia saat ini. Ini telah mencapai performa tingkat atas dalam toleransi fitur wajah, presisi, dan daya tarik estetika, dengan keunggulan yang jelas dalam fungsi individu. Peluncurannya diharapkan dapat meningkatkan aplikasi digital human dan video musik AI secara signifikan dan membawa lebih banyak kemungkinan ke produksi film dan televisi. OmniHuman-1 telah memberikan dampak yang mengubah permainan di bidang AI digital human, dan kami menantikan lebih banyak kejutan ketika diluncurkan secara resmi.
Artikel ini diadaptasi dari konten oleh blogger Han Qing dari AITalk, dengan terima kasih khusus.