Alibaba Digital Human Model: OmniTalker
OmniTalker: The Future of Real-Time Multimodal Interaction
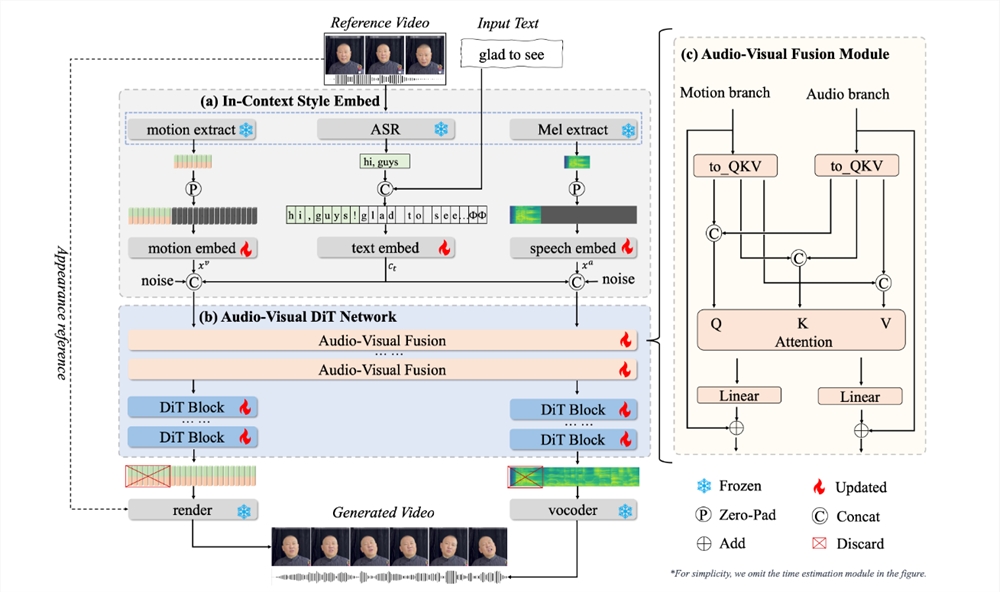
In the digital age, human-computer interaction is evolving from pure text to a more natural multimodal form (voice + video). OmniTalker, introduced by Alibaba's Tongyi Lab, is an important step in this evolution. OmniTalker is a real-time text-driven talking avatar generation framework that can convert text input into talking avatars with natural lip synchronization and supports real-time zero-shot style transfer.
Core Features and Technical Breakthroughs
Multimodal Fusion
OmniTalker supports the joint processing of four types of inputs: text, images, audio, and video, enabling the generation of richer and more natural interactive content.
Real-Time Interaction
The real-time capability of OmniTalker is one of its major highlights. With a model size of only 0.8B parameters and an inference speed of up to 25 frames per second, it can support real-time interactive scenarios such as AI video assistants and real-time virtual anchors.
Precise Synchronization
OmniTalker employs TMRoPE (Time-aligned Multimodal Rotary Position Embedding) technology to control the audio-video alignment error within ±40ms, ensuring high-precision temporal alignment of audio and video.
Zero-Shot Style Transfer
OmniTalker can simultaneously extract voice and facial styles from a single reference video without the need for additional training or style extraction modules, achieving zero-shot style transfer.
Application Scenarios
The application scenarios for OmniTalker are extensive, including but not limited to:
Virtual Assistants
OmniTalker can be integrated into conversational systems to support real-time virtual avatar dialogue.
Video Chats
In video chats, OmniTalker can generate natural lip synchronization and facial expressions.
Digital Human Generation
OmniTalker can generate digital avatars with personalized features.
Project Background and Motivation
With the development of large language models (LLMs) and generative AI, the demand for human-computer interaction to evolve from pure text to multimodal forms is increasing. Traditional text-driven talking avatar generation relies on cascaded pipelines, which have issues such as high latency, asynchronous audio and video, and inconsistent styles. OmniTalker aims to address these pain points and promote a more natural and real-time interactive experience.
Experience OmniTalker
The OmniHuman platform is set to integrate the OmniTalker model soon – stay tuned. The OmniTalker model will offer users powerful real-time text-driven talking avatar generation capabilities, supporting natural lip synchronization and real-time zero-shot style transfer. Users will be able to directly experience the powerful features of OmniTalker on the OmniHuman platform.