
O Desempenho Impressionante do OmniHuman-1
</p> Nos campos de humanos digitais e tecnologia de sincronização labial com IA, a equipe AI.TALK, aproveitando sua profunda expertise no setor e vasta experiência prática, criou aproximadamente 300 humanos digitais. Eles experimentaram quase todas as tecnologias de humanos digitais de código aberto e proprietárias disponíveis no mercado, acumulando uma riqueza de experiência prática. Após participar do teste beta do OmniHuman-1, a equipe deu a este produto um elogio excepcionalmente alto,
considerando-o o melhor produto de humano digital com IA disponível hoje—sem exceção.
Isso é um exagero? Vejamos este exemplo:

<iframe
style="width: 100%; height: auto; aspect-ratio: 16/9;" src="https://cdn.omnihuman1.org/video/0b2edmabwaaamaapygfymbtvag6ddmnqagya.f10002.mp4"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen>
</iframe>A força do OmniHuman-1 reside em sua capacidade de alcançar perfeitamente a sincronização labial para humanos digitais em vistas de perfil, reconhecer automaticamente letras de música e permitir que humanos digitais baseados em imagem balancem naturalmente e interajam com instrumentos musicais.
Agora, vamos dar uma olhada no seguinte segmento:
A clareza da boca é excepcionalmente alta, e mesmo em condições desafiadoras, como obstrução do microfone ou iluminação complexa, a sincronização labial permanece precisa. Além disso, os personagens podem exibir uma ampla gama de emoções faciais em sincronia com a música. Essas capacidades deixaram a equipe em êxtase.
Avanços na Superação de Desafios Técnicos
A equipe foi estabelecida no início de 2023, e ao longo do caminho, eles se familiarizaram e testaram inúmeros produtos conhecidos, como D-ID e HeyGen. No entanto, esses produtos ainda enfrentam vários desafios nas seguintes áreas técnicas:
- Limitações de Características Faciais: As tecnologias tradicionais exigem o envio de fotos frontais claras e sem obstruções de indivíduos. Fotos tiradas de lado ou em ângulo ascendente frequentemente resultam em falhas de reconhecimento. Mesmo que o reconhecimento seja alcançado, os resultados gerados são significativamente comprometidos.
- Limitações Dinâmicas: Nas primeiras tecnologias de humanos digitais baseados em imagem, os movimentos corporais eram rígidos, com apenas movimentos da cabeça e da boca, faltando dinâmicas naturais do corpo.
- Limitações de Pixels: Métodos convencionais de sincronização labial frequentemente levam à degradação de pixels ao redor da boca, resultando em saída embaçada ao redor da boca, o que impacta negativamente os resultados criativos.
- Limitações de Ritmo: Quando a velocidade da fala no áudio é muito rápida, a sincronização labial do humano digital pode se desordenar, dificultando a correspondência com movimentos labiais de alta frequência.
O surgimento do OmniHuman-1 superou com sucesso esses desafios técnicos. Ele introduz uma estratégia de treinamento híbrido condicionada por movimento multimodal, permitindo que o modelo se beneficie da expansão de dados de condição mista e abordando a escassez de dados de alta qualidade. OmniHuman-1 suporta entradas de imagem de qualquer proporção, sejam retratos, imagens de meio corpo ou corpo inteiro, entregando resultados vívidos e de alta qualidade em vários cenários.
O Valor Inovador do OmniHuman-1
Ele elimina as restrições de ângulo. Quando carregamos imagens para criar humanos digitais, as plataformas geralmente exigem que os usuários enviem fotos frontais claras e sem obstruções de indivíduos. A razão é simples: o núcleo dessa tecnologia depende do reconhecimento preciso das características faciais. Se falhar, prompts como "Não foi possível reconhecer o rosto" aparecerão. Portanto, fotos como as abaixo são definitivamente inaceitáveis, pois ângulos laterais ou ascendentes frequentemente levam a falhas de reconhecimento. Às vezes, com sorte, um ângulo lateral de 45 graus pode ser reconhecido, mas os resultados gerados serão significativamente comprometidos, com problemas como bocas distorcidas sendo comuns.


Agora, vamos dar uma olhada no desempenho do OmniHuman-1 com perfis laterais de 90 graus e ângulos ascendentes:
A sincronização labial em ambos os vídeos é quase perfeita, acompanhada por uma ampla gama de movimentos naturais. Note que isso não é uma diferença entre desempenho forte e fraco—é uma diferença entre o que é possível e o que é impossível.
OmniHuman-1 elimina as restrições de ângulo, permitindo que personagens na produção de filmes e vídeos "desbloqueiem" uma ampla gama de ângulos de diálogo e composições de cena, não mais limitados a enfrentar a câmera diretamente. Além disso, o reconhecimento aprimorado de características faciais também aumenta a tolerância para rostos não humanos, como animais. Por exemplo, um cordeiro em estilo 3D agora pode alcançar sincronização labial básica e reconhecimento de diálogo, atendendo às necessidades da criação diária.
Além disso, o aumento da tolerância para características faciais também se reflete no reconhecimento de diferentes estilos, como os estilos de anime 2D e aquarela mencionados abaixo. Embora outros modelos também possam gerar movimentos labiais nesses estilos, em termos de completude e dinâmica dos movimentos corporais, OmniHuman-1 ainda é o melhor atualmente. Isso leva à próxima questão sobre humanos digitais baseados em imagem.
OmniHuman-1 se destaca no desempenho visual dinâmico no nível I2V (Image-to-Video). Tomemos o exemplo de Sun Wukong (o Rei Macaco): Seu reconhecimento facial é altamente preciso, e quando ele fala, todo o seu corpo e o ambiente ao redor estão em um movimento natural de alta amplitude. O movimento para cima e para baixo de sua cabeça se integra perfeitamente ao ritmo de seu corpo, e até as ondas da água sincronizam com suas ações, como se estivessem dirigindo uma geração de vídeo animado a partir de uma única imagem.
Em termos de música, OmniHuman-1 passou por otimizações direcionadas. Além de reconhecer diretamente letras de música, os rostos dos personagens também podem exibir uma ampla gama de emoções e suportar canto em grupo e performances de instrumentos.
Seu desempenho de pixels labiais é ainda mais surpreendente. Ele não apenas retém as características faciais originais do personagem, mas também alcança um nível incrivelmente alto de clareza. Por exemplo, nos detalhes de close-up da animação de Fok e de uma cantora, até os dentes gerados são reproduzidos de forma extremamente natural.
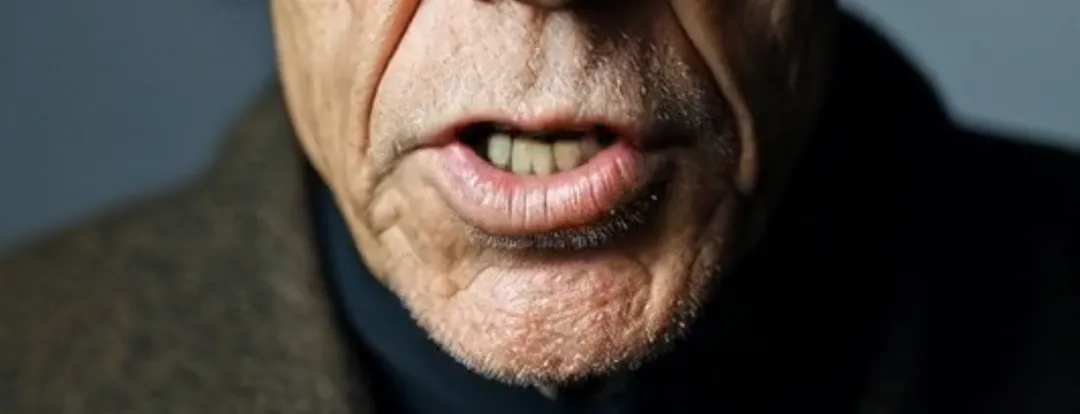
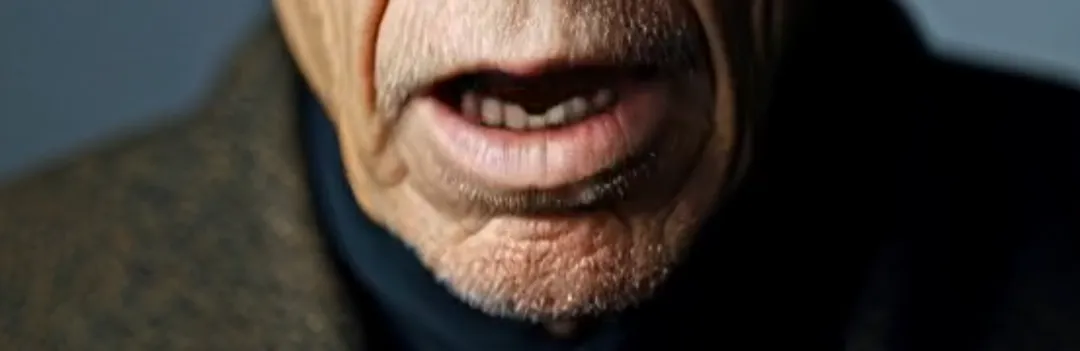



Em seguida, está o reconhecimento de pixels, que envolve dois elementos que frequentemente interferem na sincronização labial: iluminação forte e barbas longas. O primeiro pode causar falhas na geração de vídeo em imagens com contrastes intensos de luz e sombra. No Runway, ele avisaria “contraste excessivo de luz e sombra”. Por exemplo, em um vídeo de exemplo, uma pessoa idosa sentada em um carro tem sombras constantemente mudando em seu rosto. Além do OmniHuman-1, quase nenhuma outra plataforma pode substituir com sucesso os lábios. Barbas longas, por outro lado, frequentemente causam embaçamento ao redor da boca. No entanto, como visto nos clipes de exemplo, OmniHuman-1 pode reproduzir quase perfeitamente as barbas sem perda de detalhes.
Impressionante, não há outras palavras para descrever.
O desafio final é o problema de falar muito rápido. Qualquer pessoa com experiência já encontrou isso: quando a taxa de fala no áudio que você fornece é muito rápida, a sincronização labial do humano digital definitivamente se desordenará. Isso ocorre porque a taxa de quadros da animação luta para corresponder às mudanças de alta frequência nos movimentos labiais, resultando em uma incompatibilidade. No entanto, OmniHuman-1 também resolveu muito bem esse problema. No segmento com Steve Jobs falando em um ritmo extremamente rápido, quase não há falhas na sincronização labial. Mesmo para música rap, não deve ser um problema.
Problemas Existentes e Perspectivas Futuras
Apesar de seus avanços tecnológicos significativos, OmniHuman-1 ainda tem áreas para melhorar. Atualmente, OmniHuman-1 não oferece nenhuma função de ajuste fino. Por exemplo, quando os personagens falam, a amplitude de seus movimentos pode ser muito grande. Sugere-se que sejam adicionadas opções para ajustar a amplitude dos movimentos corporais e fornecer mais escolhas para ações dos membros. Além disso, OmniHuman-1 atualmente suporta apenas animações impulsionadas por imagem e ainda não suporta sincronização labial em vídeo. Espera-se que esse recurso seja introduzido em breve. A limitação atual de 15 segundos para o conteúdo gerado não é curta, mas ainda há espaço para melhorias. Em termos de velocidade de geração, durante a fase de teste interno, leva aproximadamente 15-20 minutos para gerar um único clipe. Espera-se que esse processo seja otimizado e mais eficiente quando o produto for lançado oficialmente.
Resumo
Com suas fortes capacidades técnicas e desempenho excepcional, OmniHuman-1 é, sem dúvida, o melhor produto de humano digital com IA disponível atualmente. Ele alcançou um desempenho de alto nível em tolerância de características faciais, precisão e apelo estético, com vantagens claras em funções individuais. Seu lançamento deve impulsionar significativamente a aplicação de humanos digitais e vídeos musicais com IA e trazer mais possibilidades para a produção de filmes e televisão. OmniHuman-1 teve um impacto transformador no campo de humanos digitais com IA, e esperamos mais surpresas quando ele for lançado oficialmente.
Este artigo é adaptado do conteúdo do blogueiro Han Qing da AITalk, com agradecimentos especiais.